Завдання штучного інтелекту 7 Тест по темі «Історія розвитку штучного інтелекту» 9
|
Скачати 236.36 Kb.
|
|
| Дата конвертації | 25.03.2018 |
| Розмір | 236.36 Kb. |
| Тип | реферат |
|
|
-
Навігація по даній сторінці:
- Визначення штучного інтелекту
- Історія розвитку штучного інтелекту
- Завдання штучного інтелекту
- Основні підходи до дослідження штучного інтелекту
- Основні напрямки досліджень в області штучного інтелекту
- Визначення інтелектуальної інформаційної системи
- Класифікація інтелектуальних систем
- Класифікація моделей подання знань
- Класифікація штучних нейронних мереж
- Одношарові штучні нейронні мережі
- Багатошарові нейронні мережі
- Завдання, які вирішуються нейронними мережами
- Схема функціонування генетичного алгоритму
- Види генетичних алгоритмів
- Теорія нечітких множин
- Модель експертних систем
- Класифікація експертних систем і оболонок експертних систем
- Засоби розробки експертних систем
- Структура систем підтримки прийняття рішень
- Класифікація систем підтримки прийняття рішень
|
зміст Частина 1. Введення в штучний інтелект .. 2 §1. Історія розвитку штучного інтелекту як науки. 2 Визначення штучного інтелекту. 2 Історія розвитку штучного інтелекту. 3 Завдання штучного інтелекту. 6 Тест по темі «Історія розвитку штучного інтелекту». 8 §2. Напрями та підходи до досліджень в області штучного інтелекту 9 Основні підходи до дослідження штучного інтелекту. 9 Основні напрямки досліджень в області штучного інтелекту. 11 Тест по темі «Напрямки і підходи досліджень в області штучного інтелекту» 16 §3. Класифікація інтелектуальних інформаційних систем .. 18 Визначення інтелектуальної інформаційної системи .. 18 Класифікація інтелектуальних систем .. 19 Тест по темі «Класифікація інтелектуальних інформаційних систем». 26 Частина 2. Основи теорії штучного інтелекту .. 28 §1. Подання знань. 28 Дані і знання. 28 Класифікація моделей уявлення знань. 32 Тест по темі «Представлення знань». 40 §2. Нейронні мережі. 42 Класифікація штучних нейронних мереж. 45 Одношарові штучні нейронні мережі. 46 Багатошарові нейронні мережі. 48 Завдання, які вирішуються нейронними мережами. 50 Тест по темі «Нейронні мережі»: 51 §3. Еволюційне моделювання. 53 Генетичні алгоритми .. 56 Схема функціонування генетичного алгоритму. 57 Види генетичних алгоритмів. 63 Тест по темі «Еволюційний моделювання». 66 §4. Нечіткі множини і нечітка логіка. 68 Теорія нечітких множин. 70 Нечітка логіка. 73 Тест по темі «Нечіткі безлічі і нечітка логіка». 79 Частина 3. Інтелектуальні інформаційні системи ... 82 §1. Експертні системи .. 82 Модель експертних систем .. 85 Класифікація експертних систем і оболонок експертних систем .. 87 Засоби розробки експертних систем .. 89 Тест по темі «Експертні системи». 92 §2. Системи підтримки прийняття рішень. 94 Структура систем підтримки прийняття рішень. 96 Класифікація систем підтримки прийняття рішень. 99 Тест по темі «Системи підтримки прийняття рішень». 103 Рекомендована література .. 105 Глосарій .. 108
§1. Історія розвитку штучного інтелекту як науки Визначення штучного інтелектуТермін «штучний інтелект» (artificial intelligence) був запропонований в 1956 р Слово intelligence означає «уміння міркувати розумно», а зовсім не «інтелект», для якого є термін intellect. Штучний інтелект займається вивченням розумної поведінки (у людей, тварин і машин) і спроба знайти способи моделювання подібної поведінки в будь-якому типі штучно створеного механізму. Незважаючи на те, що терміну більше півстоліття єдиного визначення не існує. Різні дослідники по-різному визначають цю науку, в залежності від свого погляду на неї і працюють над створенням систем, які - думають подібно людям; - думають раціонально; - діють подібно людям; - діють раціонально. Синтезуючи десятки визначень штучного інтелекту з різних джерел як робоче визначення можна запропонувати наступне. Штучний інтелект - це один з напрямків інформатики, метою якого є розробка апаратно-програмних засобів, що дозволяють користувачеві-непрограмістів ставити і вирішувати свої, що традиційно вважаються інтелектуальними завдання, спілкуючись з ЕОМ на обмеженій підмножині природної мови. При відтворенні розумних міркувань і дій виникають певні труднощі. По-пір'яних в більшості випадків, виконуючи якісь дії, людина не усвідомлює, як це робить, ніхто не знає точний спосіб, метод або алгоритм розуміння тексту, розпізнавання осіб, доказів теорем, рішення задач, твори віршів і т.д. По-друге, на сучасному рівні розвитку комп'ютер занадто далекий від людського рівня компетентності і працює за іншими принципами. Штучний інтелект завжди був міждисциплінарної наукою, будучи одночасно і наукою і мистецтвом, і технікою і психологією. Методи штучного інтелекту різноманітні. Вони активно запозичуються з інших наук, адаптуються і змінюються під решаемую завдання. Для створення інтелектуальної системи необхідно залучати фахівців з прикладної області, в рамках штучного інтелекту співпрацюють лінгвісти, нейрофізіологи, психологи, економісти, інформатики, програмісти і т.д. Історія розвитку штучного інтелектуІдея створення штучного подібності людини для вирішення складних завдань і моделювання людського розуму витала в повітрі ще в найдавніші часи. Так, в стародавньому Єгипті була створена «оживає» механічна статуя бога Амона. У Гомера в «Іліаді» бог Гефест кував людиноподібних істот. Штучний інтелект є в деякому сенсі наукою майбутнього, в якій немає жорсткого поділу по областям і ясно видно зв'язок між окремими дисциплінами, які лише відображають певну грань пізнання. Точний звід законів, керівних раціональної частиною мислення, був сформульований Аристотелем (384-322 роки до н.е.) Однак родоначальником штучного інтелекту вважається середньовічний іспанський філософ, математик і поет Раймонд Раймунд, який ще в XIII столітті спробував створити механічну машину для вирішення різних задач, на основі розробленої ним загальної класифікації понять. У XVIII столітті Лейбніц і Декарт незалежно один від одного продовжили цю ідею, запропонувавши універсальні мови класифікації всіх наук. Ці роботи можна вважати першими теоретичними роботами в галузі штучного інтелекту. Теорія ігор і теорія прийняття рішень, дані про будову мозку, когнітивна психологія - все це стало будівельним матеріалом для штучного інтелекту. Але остаточне народження штучного інтелекту як наукового напрямку відбулося тільки після створення ЕОМ в 40-х роках XX століття і випуску Норбертом Вінером основоположних робіт по новій науці - кібернетиці. Формування штучного інтелекту як науки відбулося в 1956 році. Д. Маккарті, М. Мінський, К. Шеннон і Н. Рочестер організували двомісячний семінар в Дартмуті для американських дослідників, що займаються теорій автоматів, нейронними мережами, інтелектом. Хоча дослідження в цій області вже активно велися, але саме на цьому семінарі з'явилися термін і окрема наука - штучний інтелект. Одним із засновників теорії штучного інтелекту вважається відомий англійський учений Алан Тьюринг, який в 1950-му році опублікував статтю «Обчислювальні машини й розум» (перекладену на російську мову під назвою «Чи може машина мислити?»). Саме в ній описувався, що став класичним «тест Тьюринга», що дозволяє оцінити «інтелектуальність» комп'ютера по його здатності до осмисленого діалогу з людиною. Перші десятиліття розвитку (1952-1969) штучного інтелекту були сповнені успіхів і ентузіазму. А. Ньюелл, Дж. Шоу і Г. Саймон створили програму для гри в шахи, на основі методу, запропонованого в 1950 році К. Шенноном, формалізованого А. Тьюрингом і промоделювати їм же вручну. До роботи була залучена група голландських психологів під керівництвом А. де Гроота, які вивчали стилі гри видатних шахістів. У 1956 році цим колективом була створена мова програмування ІПЛ1 - практично перший символьний мову обробки списків і написана перша програма "Логік-Теоретик", призначена для автоматичного доведення теорем в численні висловів. Цю програму можна віднести до перших досягнень в області штучного інтелекту. У 1960 році цією ж групою написана програма GPS (General Problem Solver) - універсальний вирішувач завдань. Вона могла вирішувати ряд головоломок, обчислювати невизначені інтеграли, вирішувати деякі інші завдання. Ці результати привернули увагу фахівців в області обчислень і з'явилися програми автоматичного доведення теорем з планіметрії і розв'язання алгебраїчних задач. З 1952 року А. Самюел написав ряд програм для гри в шашки, які грали на рівні добре підготовленого любителя, причому одна з його ігор навчилася грати краще, ніж її творець. У 1958 році Д. Маккарті визначив нову мову високого рівня Lisp, який став домінуючим для штучного інтелекту. Перші нейромережі з'явилися в кінці 50-х років. У 1957 році Ф. Розенблатта була зроблена спроба створити систему, що моделює людське око і його взаємодію з мозком - перцептрон. Перша міжнародна конференція з питань штучного інтелекту (IJCAI) відбулася в 1969 році у Вашингтоні. У 1963 р Д. Робінсон реалізував метод автоматичного доведення теорем, що отримав назву «принцип резолюції», в основі цього методу в 1973 році створюється мова логічного програмування Prolog. У США з'явилися перші комерційні системи, засновані на знаннях, - експертні системи. Відбувається комерціалізація штучного інтелекту. Ростуть щорічні капіталовкладення і інтерес до самонавчальним системам, створюються промислові експертні системи. Розробляються методи представлення знань. Перша експертна система була створена Е. Фейгенбаум в 1965 році. Але до комерційного прибутку було ще далеко. Лише в 1986 році перша комерційна система R1 компанії DEC дозволила заощадити приблизно 40 мільйонів доларів на рік. У 1988 році компанією DEC було розгорнуто 40 експертних систем. У компанії Du Pont застосовувалося 100 систем і економія становила приблизно 10 мільйонів в рік. У 1981 році Японія приступила до розробки комп'ютера 5-го покоління, заснованого на знаннях - 10-річного плану по розробці інтелектуальних комп'ютерів на базі Prolog. 1986 рік став роком відродження інтересу до нейронних мереж. У 1991 році Японія припиняє фінансування проекту комп'ютера 5-го покоління і починає проект створення комп'ютера 6-го покоління - нейрокомп'ютера. У 1997 році комп'ютер «Діп Блю» переміг в грі в шахи чемпіона світу Г. Каспарова, довівши можливість того, що штучний інтелект може зрівнятися або перевершити людини в ряді інтелектуальних завдань (нехай і в обмежених умовах). Величезну роль в боротьбі за визнання штучного інтелекту в нашій країні зіграли академіки А. І. Берг і Г. С. Поспєлов. У 1954-1964 рр. створюються окремі програми і проводяться дослідження в області пошуку рішення логічних задач. Створюється програма АЛПЕВ ломи, автоматично доводить теореми. Вона заснована на оригінальному зворотному виведення Маслова, аналогічному методу резолюцій Робінсона. Серед найбільш значущих результатів, отриманих вітчизняними вченими в 60-і роки, слід відзначити алгоритм «Кора» М. М. Бонгард, що моделює діяльність людського мозку при розпізнаванні образів. Великий внесок у становлення російської школи штучного інтелекту внесли видатні вчені М. Л. Цетлін, В. Н. Пушкін, М. А. Гаврилов, чиї учні і з'явилися піонерами цієї науки в Росії. У 1964 рпропонувався метод автоматичного пошуку доведення теорем в численні предикатів, який отримав назву «зворотний метод Маслова». У 1965-1980 рр. відбувається народження нового напрямку - ситуаційного управління (відповідає уявленню знань, в західній термінології). Засновником цієї наукової школи став проф. Д. А. Поспєлов. У Московському державному університеті був створений мову символьного обробки даних РЕФАЛ В.Ф. Турчиним в 1968. Завдання штучного інтелектуШтучний інтелект переслідує безліч цілей. Однією з основних завданням штучного інтелекту є створення повного наукового опису інтелекту людини, тваринного і машини і обчислення принципів, спільних для всіх трьох. Моделювання розуму необхідно для вирішення завдань. До інтелектуальних завдань можна віднести всі завдання, алгоритм знаходження яких невідоме. Але, наприклад, перебір всіх можливих комбінацій також є алгоритмом. Застосувати його на практиці, на жаль, на сучасному рівні розвитку техніки до більшості завдань неможливо (сучасна ЕОМ не зможе згенерувати всі прості перестановки більш ніж 12 різних предметів, яких більше 479 млн.). Комбінаторний вибух, з яким зіткнулися дослідники вже в ранніх дослідженнях - приклад цього. У таких випадках, коли незначне збільшення вхідних даних задачі веде до зростання кількості повторюваних дій в статечної залежності, говорять про неполіноміальних алгоритмах, які характеризуються тим, що кількість операцій в них зростає в залежності від числа входів за законом, близькому до експоненті. Подібні алгоритми рішення має надзвичайно велике коло завдань, особливо комбінаторних проблем, пов'язаних з перебуванням поєднань, перестановок, розміщень будь-яких об'єктів. Тому труднорешаемой (нездійсненним) завданням можна називати таку задачу, для якої не існує ефективного алгоритму рішення. Експонентні алгоритми рішень, в тому числі і вичерпні, абсолютно неефективні для випадків, коли вхідні дані змінюються в досить широкому діапазоні значень, отже, в загальному випадку вважати їх ефективними не можна. Ефективний алгоритм має не настільки різко зростаючу залежність кількості обчислень від вхідних даних, наприклад обмежено поліноміальних, тобто х знаходиться в підставі, а не в показнику ступеня. Такі алгоритми називаються поліноміальними, і, як правило, якщо завдання має поліноміальний алгоритм рішення, то вона може бути вирішена на ЕОМ з великою ефективністю. До них можна віднести завдання сортування даних, багато завдань математичного програмування і т.п. Отже, сучасний комп'ютер не може виконати рішення повністю аналітично. Можлива заміна аналітичного рішення чисельним алгоритмом, який итеративно (тобто циклічно повторюючи операції) або рекурсивно (викликаючи процедуру розрахунку з самої себе) виконує операції, крок за кроком наближаючись до вирішення. Якщо число цих операцій зростає, час виконання, а можливо, і витрата інших ресурсів (наприклад, обмеженою машинної пам'яті), також зростає, прагнучи до нескінченності. Завдання, своїми алгоритмами рішення створюють передумови для різкого зростання використання ресурсів, в загальному вигляді не можуть бути вирішені на цифрових обчислювальних машинах, тому що ресурси завжди обмежені. Вирішенням подібних завдань і займається штучний інтелект. Дослідники вивчають процеси мислення, розумна поведінка для того, щоб знайти шляхи вирішення подібних завдань, так як людина в своїй діяльності стикається і ними досить часто і успішно вирішує. Хоча до цих пір багато завдання не вирішено, певні досягнення в цій галузі є. Досліджували використовували різні підходи і методи, щоб отримати результат. В кінці 50-х років народилася модель лабіринтового пошуку і з'явилася теорія розпізнавання образів, як наслідок початку використання ЕОМ для вирішення необчислювальних завдань. Початок 60-х років називають епохою евристичного програмування, коли використовувалися стратегії дій на основі відомих, заздалегідь заданих евристик. Евристики дозволяють скорочувати кількість розглянутих варіантів. В середині 60-х років до вирішення завдань стали активно підключати методи математичної логіки. З середини 70-х років дослідники стали приділяти увагу системам, основних на експертних знаннях. Такі системи застосовні до слабоформалізуемим завданням. Неформалізовані завдання зазвичай мають наступні особливості: - ошибочностью, неоднозначністю, неповнотою і суперечливістю вихідних даних; - ошибочностью, неоднозначністю, неповнотою і суперечливістю знань про проблемну область і розв'язуваної задачі; - великою розмірністю простору рішення, тобто перебір при пошуку рішення досить великий; - динамічно змінюються даними і знаннями. Тест по темі «Історія розвитку штучного інтелекту» 1. Які передумови виникнення штучного інтелекту як науки? a) поява ЕОМ b) розвиток кібернетики, математики, філософії, психології і т.д. c) наукова фантастика 2. В якому році з'явився термін штучний інтелект (artificial intelligence)? a) 1856 b) +1956 c) 1954 d) 1950 e) Немає правильної відповіді 3. Хто вважається родоначальником штучного інтелекту? a) А. Тьюринг b) Аристотель c) Р. Луллий d) Декарт e) Немає правильної відповіді 4. Хто створив мову Lisp? a) В. Ф. Турчин b) Д. Маккарті c) М. Мінський d) Д. Робінсон e) Немає правильної відповіді 6. Хто розробив мову РЕФАЛ? a) Д.А. Поспєлов b) Г. С. Поспєлов c) В. Ф. Турчин d) А. І. Берг e) Немає правильної відповіді 7. Хто розробив теорію ситуаційного управління? a) В. Ф. Турчин b) Г. С. Поспєлов c) Д.А. Поспєлов d) Л. І. Микулич e) Немає правильної відповіді 8. Чим знаменний 1964 рік для штучного інтелекту в Росії? a) Створено мову РЕФАЛ b) Створено Асоціацію штучного інтелекту c) Розроблено метод зворотний висновок Маслова d) Немає правильної відповіді Література по темі «Історія розвитку штучного інтелекту»: 1. Гаврилова Т.А. Проблеми штучного інтелекту. http://www.big.spb.ru/publications/bigspb/km/problems_ai.shtml 2. Гаврилова Т.А., Хорошевський В.Ф. Бази знань інтелектуальних систем. СПб .: Пітер, 2001. с. 384. 3. Лорьер Ж.-Л. Системи штучного інтелекту. - М .: Світ, 1991. - 568с. 4. Рассел С., Норвіг П. Штучний інтелект: сучасний підхід, 2-е вид. - М .: Вільямс, 2006. - с. 1408. 5. Уитби Б. Штучний інтелект: реальна чи Матриця. - М .: ФАИР-ПРЕСС, 2004. - с. 224. 6. Чого не може комп'ютер, або труднорешаемие завдання штучного інтелекту. http://www.algoritmy.info/hardtask.html 7. Ясницький Л.Н. Введення в штучний інтелект. - М .: Видавничий центр «Академія», 2005. - 176 с. §2. Напрями та підходи до досліджень в області штучного інтелекту Основні підходи до дослідження штучного інтелектуНезабаром після визнання штучного інтелекту окремою галуззю науки відбувся поділ його на два напрямки: нейрокібернетика і кібернетика чорного ящика. Ці напрямки розвиваються практично незалежно, істотно розрізняючись як в методології, так і в технології. Нейрокібернетики взяли за основу структуру і принципи функціонування єдиного створеного природою пристрою, здатного міркувати - мозку. Клітини мозку називаються нейронами, звідси і назва напряму. Дослідники вважали, що, змоделювавши мозок, зможуть відтворити і його роботу. Дослідники напрямки кібернетика чорного ящика дотримувалися думки, що не важливо за якими принципами працює пристрій, які засоби і методи лежать в його основі, головне, імітувати функції мозку, навіть якщо крім результату це не матиме нічого спільного з природним розумом. Нині стали помітні тенденції до об'єднання цих частин знову в єдине ціле. Стало з'являтися безліч гібридних методів і систем, наприклад, експертна система на базі нейронної мережі або нейронна мережа, навчається генетичним алгоритмом. Дослідники, що моделюють лише окремі функції інтелекту, наприклад, розпізнавання образів, синтез мови, прийняття рішень, працюють у рамках напряму слабкий штучний інтелект. Спроби відтворити роботу інтелекту в повному обсязі відносяться до напрямку сильний штучний інтелект. Всі основні досягнення в області штучного інтелекту відносяться до слабкого штучного інтелекту. Крім цього, виділяють спадний (семіотичний) і висхідний (біологічний) підходи. Спадний підхід передбачає моделювання високорівневих психічних процесів, таких як мислення, мова, емоції і т.д. Висхідний підхід досліджує інтелектуальну поведінку систем на базі більш дрібних «неінтелектуальних» елементів. Нейронні мережі та еволюційне моделювання відносяться до цього підходу. Інтелектуальні системи розробляються із залученням різних засобів і методів. Існує чотири основні підходи до їх побудови: логічний, структурний, еволюційний і імітаційний. Основою для даного логічного підходу служить Булева алгебра. Така інтелектуальна система являє собою машину доведення теорем. При цьому вихідні дані зберігаються в базі даних у вигляді аксіом, правила логічного висновку як відносини між ними. Крім того, кожна така машина має блок генерації цілі, і система виведення намагається довести дану мету як теорему. Якщо мета доведена, то трасування застосованих правил дозволяє отримати ланцюжок дій, необхідних для реалізації поставленої мети. Потужність такої системи визначається можливостями генератора цілей і машиною доведення теорем. Для більшості логічних методів характерна велика трудомісткість, оскільки під час пошуку докази можливий повний перебір варіантів. Тому даний підхід вимагає ефективної реалізації обчислювального процесу, і хороша робота зазвичай гарантується при порівняно невеликому розмірі бази даних. Під структурним підходом мається на увазі спроби побудови інтелектуальної системи шляхом моделювання структури людського мозку, тобто системи, побудовані в рамках напряму нейрокібернетика. При побудові інтелектуальної системи за допомогою еволюційного підходу основна увага приділяється побудові початкової моделі, і правилам, за якими вона може змінюватися (еволюціонувати). Причому модель може бути складена з найрізноманітніших методів, це може бути і нейронна мережа і набір логічних правил і будь-яка інша модель. На підставі перевірки моделей відбирає найкращі з них, на підставі яких по самим різним правилам генеруються нові моделі, з яких знову вибираються найкращі і т. Д. Імітаційний підхід використовується в рамках напряму кібернетика чорного ящика. Інтелектуальні системи при такому підході повинні моделювати якусь інтелектуальну функцію, тобто встановити необхідне відповідність між входами і виходами системи. Основні напрямки досліджень в області штучного інтелектуТематика штучного інтелекту охоплює величезний перелік наукових напрямків, починаючи з таких завдань загального характеру, як навчання і сприйняття, і закінчуючи такими спеціальними завданнями, як гра в шахи, доказ математичних теорем, твір поетичних творів і діагностика захворювань. У штучному інтелекті систематизуються і автоматизуються інтелектуальні завдання і тому ця область стосується будь-якої сфери інтелектуальної діяльності людини. Серед безлічі напрямків штучного інтелекту є кілька ведучих, які в даний час викликають найбільший інтерес у дослідників і практиків. Подання знань і розробка систем, заснованих на знаннях Це основний напрямок в області розробки систем штучного інтелекту. Воно пов'язане з розробкою моделей представлення знань, створенням баз знань, які становлять ядро експертних систем. Програмне забезпечення систем штучного інтелекту В рамках цього напрямку розробляються спеціальні мови для вирішення інтелектуальних завдань, в яких наголос робиться на переважання логічного і символьної обробки над обчислювальними процедурами. Мови орієнтовані на символьну обробку інформації - LISP, PROLOG, РЕФАЛ і ін. Крім цього створюються пакети прикладних програм, орієнтовані на промислову розробку інтелектуальних систем, або програмні інструментарії штучного інтелекту. Розробка природно-мовних інтерфейсів і машинний переклад Починаючи з 50-х років однією з популярних тем досліджень в галузі штучного інтелекту є комп'ютерна лінгвістика, і, зокрема, машинний переклад. Ідея машинного перекладу виявилася зовсім не так проста, як здавалося першим дослідникам і розробникам. інтелектуальні роботи Роботи - це електротехнічні пристрої, призначені для автоматизації людської праці. Виділяють кілька поколінь роботів: I покоління. Роботи з жорсткою схемою управління. Практично всі сучасні промислові роботи належать до першого покоління. Фактично це програмовані маніпулятори. II покоління. Адаптивні роботи з сенсорними пристроями. Є зразки таких роботів, але в промисловості вони поки використовуються мало. III покоління. Самоорганізуються або інтелектуальні роботи. Це - кінцева мета розвитку робототехніки. Основні невирішені проблеми при створенні інтелектуальних роботів - проблема машинного зору і адекватного зберігання і обробки тривимірної візуальної інформації. В даний час в світі виготовляється більше 60 000 роботів в рік. Фактично робототехніка сьогодні - це інженерна наука, не відкидаєш технологій штучного інтелекту, але не готова поки до їх впровадження в силу різних причин. Навчання і самонавчання Активно розвивається область штучного інтелекту. Включає моделі, методи і алгоритми, орієнтовані на автоматичне накопичення і формування знань на основі аналізу та узагальнення даних, навчання за прикладами (або індуктивний), а також традиційні підходи з теорії розпізнавання образів. В останні роки до цього напрямку тісно примикають стрімко розвиваються системи аналізу даних і пошуку закономірностей в базах даних. Розпізнавання образів Напрямок штучного інтелекту, що бере початок у самих його витоків, але в даний час виділилася в самостійну науку. Її основний підхід - опис класів об'єктів через певні значення значущих ознак. Кожному об'єкту ставиться у відповідність матриця ознак, по якій відбувається його розпізнавання. Процедура розпізнавання використовує найчастіше спеціальні математичні процедури і функції, що розділяють об'єкти на класи. Цей напрямок близько до машинного навчання і тісно пов'язане з нейрокібернетики. Нові архітектури комп'ютерів Найсучасніші процесори сьогодні засновані на традиційній послідовній архітектурі фон Неймана, використовуваної ще в комп'ютерах перших поколінь, Ця архітектура вкрай неефективна для символьної обробки. Тому зусилля багатьох наукових колективів і фірм вже десятки років націлені на розробку апаратних архітектур, призначених для обробки символьних і логічних даних. Створюються Пролог- і Лісп-машини, комп'ютери V і VI поколінь. Останні розробки присвячені комп'ютерам баз даних, паралельним і векторних комп'ютерів. І хоча вдалі промислові рішення існують, висока вартість, недостатнє програмне оснащення і апаратна несумісність з традиційними комп'ютерами істотно гальмують широке використання нових архітектур. ігри Це, стало швидше історичним, напрямок пов'язаний з тим, що на зорі досліджень штучного інтелекту традиційно включав в себе ігрові інтелектуальні завдання - шахи, шашки, го. В основі перших програм лежить один з ранніх підходів - лабіринтова модель мислення плюс евристики. Зараз це швидше комерційний напрямок, так як в науковому плані ці ідеї вважаються тупиковими. В даний час в комп'ютерних іграх (наприклад, Unreal Tournament, Return to Castle Wolfe Stein, Black & White, Doom, Sim) стали застосовуватися інші ідеї штучного інтелекту - нейронні мережі, інтелектуальні агенти, генетичні алгоритми і т.д., які дозволяють створювати персонажів (ботів) з різним ступенем «інтелекту». Використання методів штучного інтелекту в іграх дозволяє отримувати нові ефективні рішення, створювати шаблони проектування, підвищити розважальність і достовірність ігор. машинне творчість Напрямок охоплює твір комп'ютером музики (Айзексон, Хіллер, Зармпов), віршів (Д. Лінк), живопису (Х. Фарід, Л. Моура) і навіть казок і афоризмів. Основним методом подібного «творчості» є метод пермутації (перестановок) плюс використання деяких баз знань і даних, що містять результати досліджень по структурам текстів, рим, сценаріями і т. П. Нечіткі моделі та м'які обчислення. Цей напрямок представлено нечіткими схемами «виведення за аналогією», поглядом на теорію нечітких заходів з імовірнісних позицій, нечітким поданням аналітичними моделями для опису геометричних об'єктів, алгоритмами еволюційного моделювання з динамікою, такими як час життя і розмір популяції, методами вирішення оптимізаційних задач з використанням технологій генетичного пошуку, гомеостатических і синергетичних принципів і елементів самоорганізації. евристичне програмування В рамках напряму досліджують послідовності розумових операцій, виконання яких призводить до успішного вирішення того чи іншого завдання, моделюють розумову діяльність людини для вирішення завдань, що не мають суворого формалізованого алгоритму або пов'язаних з неповнотою вихідних даних. штучна життя Напрямок досліджень, метою якого є створення штучних істот, здатних діяти не менш ефективно, ніж живі істоти. М'яка штучне життя створює обчислювальні системи і моделі, що діють на базі біологічних і еволюційних принципів. Волога штучне життя синтезує нові штучні біологічні форми. В рамках цього напрямку використовують генетичні алгоритми, клітинні автомати, автономні агенти і т.д. когнітивне моделювання Науковий напрямок, що є плідним синтезом когнітивної графіки і обчислювального моделювання, що дозволяє істотно підвищити пізнавальну ефективність сучасних ЕОМ. Методологія когнітивного моделювання призначена для аналізу і прийняття рішень в погано певних ситуаціях, ґрунтується на моделюванні суб'єктивних уявлень експерта. еволюційне моделювання При еволюційному моделюванні процес моделювання складної соціально-економічної системи зводиться до створення моделі його еволюції або до пошуку допустимих станів системи, до процедури (алгоритму) відстеження безлічі допустимих станів (траєкторій). багатоагентні системи Напрямок штучного інтелекту, яке розглядає рішення однієї задачі кількома інтелектуальними підсистемами - агентами. Агент - апаратна або програмна сутність, здатна діяти в інтересах досягнення мети, поставленої перед всією системою. Соціальні системи дають ще одне модельне уявлення інтелекту за допомогою глобального поведінки, яке дозволяє їм вирішувати проблеми, які б не вдалося вирішити окремим їх членам. Агенти в таких системах автономні або напівавтономних, у кожного агента є певне коло підзадач, причому він має в своєму розпорядженні малим знанням (або зовсім не має в своєму розпорядженні знанням) про те, що роблять інші агенти або як вони це роблять. Кожен агент виконує свою незалежну частину рішення проблеми і або видає власне результат (щось робить) або повідомляє результат іншим агентам. онтології В рамках цього напрямку досліджується можливість всеосяжної і детальної формалізації деякої області знань за допомогою концептуальної схеми - ієрархічної структури даних, що містить всі релевантні класи об'єктів, їх зв'язку і правила предметної області. Онтології використовуються і людьми і програмними агентами, дозволяють повторно використовувати знання предметної області, відокремити їх від оперативних знань і аналізувати їх. Розробляються мови опису онтологій (RDF, DAML, OWL, KIF). Комп'ютерні віруси Останнє покоління комп'ютерних вірусів володіють всіма атрибутами систем штучного інтелекту. Вони здатні до розмноження, мутації, еволюції, навчання. Сучасні проблеми щодо захисту від них виявляться незначними, коли вони повністю проникнуть в сферу штучного інтелекту. Методи штучного інтелекту необхідні як для їх створення, так і для розробки ефективних засобів захисту. Інтелектуальне математичне моделювання В даному напрямку системи імітують творчу діяльність математика-професіонала, що займається рішенням, наприклад, крайових задач математичної фізики. Для цього використовуються бази знань, що містять теореми, математичні залежності, евристичні правила, такі системи здатні до навчання і самонавчання. Це далеко не всі напрямки штучного інтелекту, існує безліч напрямків для вирішення безлічі завдань. Тест по темі «Напрямки і підходи досліджень в області штучного інтелекту» 1. Який із напрямів не надає значення тому, як саме моделюються функції мозку? a) нейрокібернетика b) кібернетика чорного ящика c) немає правильної відповіді 2. Який підхід використовує Булеву алгебру? a) структурний b) імітаційний c) логічний d) еволюційний e) немає правильної відповіді 3. Яку мову програмування розроблений в рамках штучного інтелекту? a) Pascal b) C ++ c) Lisp d) OWL e) PHP 4. Скільки поколінь роботів існує? a) 1 b) 2 c) 3 d) 4 5. Штучна життя має наступні напрямки? a) м'яка b) тверда c) волога d) мокра e) суха f) немає правильної відповіді 6. Які завдання вирішуються в рамках штучного інтелекту? a) розпізнавання мови b) прийняття рішень c) кодування d) створення середовищ розробки інформаційних систем e) створення комп'ютерних ігор f) немає правильної відповіді 7. Експертні знання активно використовуються в наступних напрямках? a) експертні системи b) когнітивне моделювання c) розпізнавання образів d) комп'ютерна лінгвістика e) немає правильної відповіді 8. Принцип організації соціальних систем використовується в напрямку? a) еволюційне моделювання b) когнітивне моделювання c) нейронні мережі d) немає правильної відповіді Література по темі «Напрямки і підходи досліджень в області штучного інтелекту»: 1.Гаврилова Т.А., Хорошевський В.Ф. Бази знань інтелектуальних систем. СПб .: Пітер, 2001. с. 384. 2. Підходи до побудови систем штучного інтелекту. http://ai.obrazec.ru/podhody.html 3. Рассел С., Норвіг П. Штучний інтелект: сучасний підхід, 2-е вид. - М .: Вільямс, 2006. - с. 1408. 4. Ясницький Л.Н. Введення в штучний інтелект. - М .: Видавничий центр «Академія», 2005. - 176 с. §3. Класифікація інтелектуальних інформаційних систем Визначення інтелектуальної інформаційної системиІснує велика безліч інтелектуальних інформаційних систем. Однак загальноприйнятого єдиного визначення інтелектуальної інформаційної системи немає. Інтелектуальної інформаційною системою називають автоматизовану інформаційну систему, засновану на знаннях, або комплекс програмних, лінгвістичних і логіко-математичних засобів для реалізації основного завдання - здійснення підтримки діяльності людини і пошуку інформації в режимі просунутого діалогу на природній мові. Крім того, інформаційно-обчислювальними системами з інтелектуальною підтримкою для вирішення складних завдань називають ті системи, в яких логічна обробка інформації превалює над обчислювальної. Таким чином, будь-яка інформаційна система, яка вирішує інтелектуальну задачу або в яких беруть методи штучного інтелекту, відноситься до інтелектуальних. Для інтелектуальних інформаційних систем характерні наступні ознаки: - розвинені комунікативні здібності. - вміння вирішувати складні погано формалізуються завдання. - здатність до самонавчання. - адаптивність. Комунікативні здібності ІВС характеризують спосіб взаємодії (інтерфейсу) кінцевого користувача з системою, зокрема, можливість формулювання довільного запиту в діалозі з ІВС на мові, максимально наближеному до природного. Складні погано формалізуються завдання - це завдання, які вимагають побудови оригінального алгоритму рішення в залежності від конкретної ситуації, для якої можуть бути характерні невизначеність і динамічність вихідних даних і знань. Здатність до самонавчання - це можливість автоматичного вилучення знань для вирішення завдань з накопиченого досвіду конкретних ситуацій Адаптивність - здатність до розвитку системи відповідно до об'єктивними змінами моделі проблемної області. Класифікація інтелектуальних системУ відповідності з перерахованими ознаками ІВС діляться на (рис. 1), дана класифікація одна з можливих: - системи з комутативними здібностями (з інтелектуальним інтерфейсом); - експертні системи (системи для вирішення складних завдань); - самообучающиеся системи (системи здатні до самонавчання); - адаптивні системи (адаптивні інформаційні системи).
Рис.1. Класифікація інтелектуальних інформаційних систем за типами систем. Інтелектуальні бази даних відрізняються від звичайних баз даних можливістю вибірки за запитом необхідної інформації, яка може явно не зберігатися, а виводитися з наявною в базі даних. Природно-мовний інтерфейс передбачає трансляцію природно-мовних конструкцій на Внутримашинное рівень представлення знань. Для цього необхідно вирішувати завдання морфологічного, синтаксичного і семантичного аналізу та синтезу висловлювань на природній мові. Так, морфологічний аналіз передбачає розпізнавання і перевірку правильності написання слів за словниками, синтаксичний контроль - розкладання вхідних повідомлень на окремі компоненти (визначення структури) з перевіркою відповідності граматичним правилам внутрішнього представлення знань і виявлення відсутніх частин і, нарешті, семантичний аналіз - встановлення смислової правильності синтаксичних конструкцій. Синтез висловлювань вирішує зворотну задачу перетворення внутрішнього подання інформації в природно-мовну. Природно-мовний інтерфейс використовується для: - доступу до інтелектуальних баз даних; - контекстного пошуку документальної текстової інформації ;. - голосового введення команд в системах управління; - машинного перекладу з іноземних мов. Гіпертекстові системи призначені для реалізації пошуку за ключовими словами в базах текстової інформації. Інтелектуальні гіпертекстові системи відрізняються можливістю більш складної семантичної організації ключових слів, яка відображає різні смислові відносини термінів. Таким чином, механізм пошуку працює перш за все з базою знань ключових слів, а вже потім безпосередньо з текстом. У більш широкому плані сказане поширюється і на пошук мультимедійної інформації, що включає крім текстової та цифрової інформації. Системи контекстної допомоги можна розглядати як окремий випадок інтелектуальних гіпертекстових і природно-мовних систем. На відміну від звичайних систем допомоги, які нав'язують користувачеві схему пошуку необхідної інформації, в системах контекстної допомоги користувач описує проблему (ситуацію), а система за допомогою додаткового діалогу її конкретизує і сама виконує пошук стосуються ситуації рекомендацій. Такі системи відносяться до класу систем поширення знань (Knowledge Publishing) і створюються як додаток до систем документації (наприклад, технічної документації по експлуатації товарів). Системи когнітивної графіки дозволяють здійснювати інтерфейс користувача з ІВС за допомогою графічних образів, які генеруються відповідно до подіями. Такі системи використовуються в моніторингу і управлінні оперативними процесами. Графічні образи в наочному і інтегрованому вигляді описують безліч параметрів досліджуваної ситуації. Наприклад, стан складного керованого об'єкта відображається у вигляді людського обличчя, на якому кожна риса відповідає за будь-якої параметр, а загальний вираз обличчя дає інтегровану характеристику ситуації. Системи когнітивної графіки широко використовуються також в навчальних і тренажерних системах на основі використання принципів віртуальної реальності, коли графічні -Образ моделюють ситуації, в яких хто навчається необхідно приймати рішення і виконувати певні дії. Експертних систем призначені для вирішення завдань на основі накопичуваної бази знань, що відбиває досвід роботи експертів в даній проблемній області. Багатоагентні системи. Для таких динамічних систем характерна інтеграція в базі знань декількохрізнорідних джерел знань, які обмінюються між собою одержуваними результатами на динамічної основі Для многоагентних систем характерні наступні особливості: 1. Проведення альтернативних міркувань на основі використання різних джерел знань з механізмом усунення протиріч; 2. Розподілений рішення проблем, які розбиваються на паралельно вирішуються підпроблеми, відповідні самостійним джерел знань; 3. Застосування безлічі стратегій роботи механізму виведення включень в залежності від типу розв'язуваної проблеми; 4. Обробка великих масивів даних, що містяться в базі даних; 5. Використання різних математичних моделей і зовнішніх процедур, що зберігаються в базі моделей; 6. Здатність переривання вирішення завдань в зв'язку з необхідністю отримання додаткових даних і знань від користувачів, моделей, паралельно вирішуються подпроблем. В основі самообучающихся систем лежать методи автоматичної класифікації прикладів ситуацій реальної практики. Характерними ознаками самообучающихся систем є: - самообучающиеся системи "з учителем", коли для кожного прикладу задається в явному вигляді значення ознаки його приналежності певного класу ситуацій (классообразующіх ознаки); - самообучающиеся системи "без вчителя", коли за ступенем близькості значень ознак класифікації система сама виділяє класи ситуацій. Індуктивні системи використовують узагальнення прикладів за принципом від часткового до загального. Процес класифікації прикладів здійснюється наступним чином: 1. Вибирається ознака класифікації з безлічі задані (або послідовно, або за будь-якою правилом, наприклад, відповідно до максимальним числом отриманих підмножин прикладів) 2. За значенням вибраної ознаки безліч прикладів розбивається на підмножини 3. Виконується перевірка, чи належить кожне утворилося підмножина прикладів одного підкласу 4. Якщо якесь підмножина прикладів належить одному підкласу, тобто у всіх прикладів підмножини збігається значення классообразующіх ознаки, то процес класифікації закінчуєте (при цьому інші ознаки класифікації не розглядаються) 5. Для підмножин прикладів з незбіжним значення классообразующіх ознаки процес класифікації продовжуєте, починаючи з пункту 1. (Кожне підмножина прикладів стає класифікованих безліччю). Нейронні мережі являють собою пристрої паралельних обчислень, що складаються з безлічі взаємодіючих простих процесорів. Кожен процесор такої мережі має справу тільки з сигналами, які він періодично отримує, і сигналами, які він періодично посилає іншим процесорам. В експертних системах, заснованих на прецедентах (аналогіях), база знань містить описи й не узагальнених ситуацій, а власне самі ситуації або прецеденти. Пошук рішення проблеми в експертних системах заснованих на прецедентах зводиться до пошуку по аналогії (тобто абдуктівний висновок від приватного до приватного). На відміну від інтелектуальної бази даних інформаційне сховище являє собою сховище витягнутої значимої інформації з оперативної бази даних, яке призначене для оперативного ситуаційного аналізу даних (реалізації OLAP - технології). Типовими завданнями оперативного ситуаційного аналізу є: - визначення профілю споживачів конкретних об'єктів зберігання; - передбачення змін об'єктів зберігання в часі; - аналіз залежностей ознак ситуацій (кореляційний аналіз). Адаптивна інформаційна система - це інформаційна система, яка змінює свою структуру відповідно до зміни моделі проблемної області. При цьому адаптивна інформаційна система повинна: 1. в кожен момент часу адекватно підтримувати організацію бізнес-процесів; 2. проводити адаптацію щоразу, як виникає потреба в реорганізації бізнес-процесів; 3. реконструкція інформаційної системи повинна проводитися швидко і з мінімальними витратами. Ядром адаптивної інформаційної системи є постійно розвивається модель проблемної області (підприємства), підтримувана в спеціальній базі знань - репозиторії, на основі якого здійснюється генерація або конфігурація програмного забезпечення. Таким чином, проектування і адаптація ІС зводиться, перш за все, до побудови моделі проблемної області та її своєчасному коректуванню. Так як немає загальноприйнятого визначення, чітку єдину класифікацію інтелектуальних інформаційних систем дати важко. Якщо розглядати інтелектуальні інформаційні системи з точки зору розв'язуваної задачі, то можна виділити системи управління і довідкові системи, системи комп'ютерної лінгвістики, системи розпізнавання, ігрові системи і системи створення інтелектуальних інформаційних систем (рис.2). При цьому системи можуть вирішувати не одну, а кілька завдань або в процесі вирішення одного завдання вирішувати і ряд інших.Наприклад, під час навчання іноземної мови система може вирішувати задачі розпізнавання мови учня, тестувати, відповідати на питання, перекладати тексти з однієї мови на іншу і підтримувати природно-мовної інтерфейс роботи.
Рис.2 .Классіфікація інтелектуальних інформаційних систем по важливість справ Якщо класифікувати інтелектуальні інформаційні системи за критерієм «використовувані методи», то вони діляться на жорсткі, м'які і гібридні (рис.3). М'які обчислення - це складна комп'ютерна методологія, заснована на нечіткій логіці, генетичних обчисленнях, нейрокомпьютінге і імовірнісних обчисленнях. Жорсткі обчислення - традиційні комп'ютерні обчислення (не м'які). Гібридні системи - системи, що використовують більш ніж одну комп'ютерну технологію (в разі інтелектуальних систем - технології штучного інтелекту).
Рис.3. Класифікація інтелектуальних інформаційних систем за методами Можливі й інші класифікації, наприклад, виділяють системи загального призначення і спеціалізовані системи (рис. 4).
Мал. 4. Класифікація інтелектуальних систем за призначенням Крім того, ця схема відображає ще один варіант класифікації по методам: системи, що використовують методи представлення знань, самоорганізуються і системи, створені за допомогою евристичного програмування. Також в цій класифікації системи генерації музики віднесені до систем спілкування. До інтелектуальних систем загального призначення відносяться системи, які не тільки виконують задані процедури, але на основі метапроцедур пошуку генерують і виконують процедури вирішення нових конкретних завдань. Спеціалізовані інтелектуальні системи виконують рішення фіксованого набору завдань, зумовленого при проектуванні системи. Відсутність чіткої класифікації також пояснюється різноманіттям інтелектуальних завдань і інтелектуальних методів, крім того, штучний інтелект активно розвивається наука, в якій нові прикладні області освоюються щодня. Тест по темі «Класифікація інтелектуальних інформаційних систем» 1. Інтелектуальна інформаційна система - це система ..? a) заснована на знання b) в яких логічна обробка інформації превалює над обчислювальної c) відповідає на питання d) немає правильної відповіді 2. Якщо система використовує генетичні обчислення і бази даних, вона відноситься до будь інтелектуальним системам? a) жорстким b) м'яким c) гібридним 3. Системи генерації музики можна віднести до? a) системам спілкування b) творчим системам c) системам управління d) системам розпізнавання e) немає правильної відповіді 4. Які системи є системами загального призначення? a) системи ідентифікації b) експертні системи c) нейронні мережі d) робототехнічні системи e) немає правильної відповіді 5. До самоорганизующимся систем відносяться? a) системи розпізнавання b) ігрові системи c) системи реферування текстів d) нейронні мережі e) немає правильної відповіді 6. На знаннях грунтуються системи? a) нейронні мережі b) системи розпізнавання тексту c) експертні системи d) інтелектуальні пакети прикладних програм e) немає правильної відповіді 7. Евристичний пошук використовується в? a) нейронних мережах b) експертних системах c) ігрових системах d) Немає правильної відповіді 8. До систем комп'ютерної лінгвістики належать? a) система реферування текстів b) система розпізнавання мови c) система генерації музики d) машинний переклад e) немає правильної відповіді Література по темі «Класифікація інтелектуальних інформаційних систем»: 1. Балдін К.В., Уткін В.Б. Інформатика. Підручник для вузів. - М .: Проект, 2003. с. 304. 2. Гаскаров Д.В. Інтелектуальні інформаційні системи. Підручник для вузів. - М .: Вища школа, 2003. - с. 431. 3. Ясницький Л.Н. Введення в штучний інтелект. - М .: Видавничий центр «Академія», 2005. - 176 с. Частина 2. Основи теорії штучного інтелекту §1. подання знань Дані і знанняДані - це інформація, отримана в результаті спостережень або вимірювань окремих властивостей (атрибутів), що характеризують об'єкти, процеси і явища предметної області. Знання - форма існування і систематизації результатів пізнавальної діяльності людини. Знання допомагає людям раціонально організовувати свою діяльність і вирішувати різні проблеми виникають в її процесі; суб'єктивний образ об'єктивної реальності, тобто адекватне віддзеркалення зовнішнього і внутрішнього світу в свідомості людини у формі уявлень, понять, суджень, теорій. Знання (в широкому сенсі) - сукупність понять, теоретичних побудов і уявлень. Знання (у вузькому сенсі) - ознака певного обсягу інформації, що визначає її статус і відокремлює від всієї іншої інформації за критерієм здатності до вирішення поставленого завдання. Знання (з точки зору представлення знань в інтелектуальних системах) - це зв'язки і закономірності предметної області (принципи, моделі, закони), отримані в результаті практичної діяльності і професійного досвіду, що дозволяє фахівцям ставити і вирішувати завдання в цій галузі. Знання від даних відрізняються рядом властивостей: - внутрішня интерпретируемость; - структурованість; - зв'язність; - семантична метрика; - активність. Внутрішня интерпретируемость. Дані, що зберігаються в пам'яті або на зовнішніх носіях, позбавлені імен, таким чином, відсутня можливість їх однозначної ідентифікації системою. Дані може ідентифікувати лише програма, витягати їх за певним алгоритмом. При переході до знань в пам'ять вводиться додаткова інформація (атрибути: прізвище, рік народження, спеціальність, стаж). Атрибути можуть грати роль імен. За ним можна здійснювати пошук потрібної інформації. Структурованість. Інформаційні одиниці повинні володіти гнучкою структурою. Інакше кажучи, повинна існувати можливість довільного встановлення між окремими інформаційними одиницями відносин типу «частина-ціле», «рід-вид» або «елемент-клас». Можливості підключення. Між інформаційними одиницями повинна бути передбачена можливість встановлення зв'язків різного типу. Семантика відносин може носити декларативний або процедурний характер. Наприклад, дві і більше інформаційні одиниці можуть бути пов'язані відношенням «одночасно», дві інформаційні одиниці - відношенням «причина-наслідок» або «бути поруч». Семантична метрика. На безлічі інформаційних одиниць в деяких випадках корисно задавати відношення, що характеризує їх ситуаційну близькість, тобто силу асоціативного зв'язку. Його можна було б назвати відношенням релевантності для інформаційних одиниць. Воно дає можливість виділяти в інформаційній базі деякі типові ситуації (наприклад, «покупка», «регулювання руху на перехресті»). Ставлення релевантності при роботі з інформаційними одиницями дозволяє знаходити знання, близькі до вже знайденим. Активність. Всі обчислювальні процеси ініціюються командами, а дані використовуються цими командами лише в разі потреби. Інакше кажучи, дані пасивні, а команди активні. Знання дозволяють адаптуватися і діяти в реальній дійсності. Існує величезна безліч різних знань, починаючи від рецепта приготування омлету до квантової фізики. Знання можна класифікувати за кількома критеріями (рис. 5). Знання синтаксичного типу характеризує синтаксичну структуру потоку інформації, яка не залежить від змісту і змісту, які використовуються при цьому понять, тобто інтелектуальну систему не утворює. Семантичне знання розглядається як структура, що утворює поточний контекст. Воно містять інформацію, безпосередньо пов'язану з поточними значеннями і змістом описуваних понять і визначає стан зв'язків даних в інформаційній базі. Прагматичне знання зумовлює найбільш ймовірні зв'язки, що описують дані з точки зору розв'язуваної задачі (узагальнений або "об'єктивний" контекст), наприклад, з урахуванням діючих в даній задачі специфічних критеріїв і угод. Декларативні знання містять у собі уявлення про структуру понять. Ці знання наближені до даних, фактів. Наприклад: вищий навчальний заклад є сукупність факультетів, а кожен факультет в свою чергу є сукупність кафедр.
Мал. 5. Класифікація знань Процедурні знання, мають активну природу. Вони визначають уявлення про засоби і шляхи отримання нових знань, перевірки знань. Це алгоритми різного роду. З розвитком інформатики все більша частина знань зосереджувалася в структурах даних (таблиці, списки, абстрактні типи даних), т. Е. Збільшувалася роль декларативних. Істотним для розуміння природи знань є способи визначення понять. Один з широко застосовуваних способів заснований на ідеї інтенсіонал і екстенсіонала. Інтенсіонал поняття - це визначення його через співвіднесення з поняттям більш високого рівня абстракції із зазначенням специфічних властивостей. Екстенсіонал поняття - це визначення поняття через перерахування його конкретних прикладів, т. Е. Понять більш низького рівня абстракції. Інтенсіоналом формують знання про об'єкти, в той час як екстенсіонал об'єднує дані. Звідси інтенсіональні знання - це знання про предметну область, яка відображає факти, закономірності, властивості і характеристики, справедливі для будь-яких ситуацій, які можуть виникнути в цій предметній області. Екстенсіональності знання - це знання про предметну область, що відображають факти, закономірності, властивості і характеристики, типові для конкретних ситуацій або класів однотипних ситуацій, які можуть виникнути в цій області. Функціональні знання - це знання про виконувані функції окремих предметів і про застосування їх в реальній дійсності. Технологічні знання - спеціалізовані знання, щоб забезпечити підтримку технологічних параметрів виробництва; виробничий досвід і навички, які використовуються при вирішенні повсякденних виробничих питань. Це може бути знання послідовності операцій або знання технологічного ланцюжка дозволяють досягати поставлених цілей відповідно до прийнятої технологією. Методологічні знання - знання про методи перетворення дійсності, наукові знання про побудову ефективної діяльності. До методологічних знань відносять знання цілей, форм і напрямків розвитку теорії, методів і способів ефективного перетворення практики. Класифікаційні знання застосовуються головним чином в науці, є узагальненими, системними знання.Приклад - система елементів Д.І. Менделєєва. Інтуїція - це вид знання, специфіка якого обумовлена способом його придбання. Це знання, що не потребує доведення і сприймається як достовірне. За способом отримання інтуїція - це пряме розсуд об'єктивної зв'язку речей, що не спирається на доказ (інтуїція, від лат. Intueri - споглядати, - є розсуд внутрішнім зором). Під здоровим глуздом розуміють знання дозволяють приймати правильні рішення і робити правильні припущення, ґрунтуючись на логічному мисленні і накопичений досвід. У цьому значенні термін часто акцентує увагу на здатності людського розуму протистояти забобонам, помилкам, містифікацій. Наукові знання в будь-якому випадку повинні бути обгрунтованими на емпіричної або теоретичної доказової основі. Теоретичні знання - абстракції, аналогії, схеми, що відображають структуру і природу процесів, що протікають в предметної області. Ці знання пояснюють явища і можуть використовуватися для прогнозування поведінки об'єктів. Теоретичний рівень наукового знання припускає встановлення законів, що дають можливість ідеалізованого сприйняття, описи і пояснення емпіричних ситуацій, тобто пізнання сутності явищ. Теоретичні закони мають більш строгий, формальний характер, в порівнянні з емпіричними. Терміни опису теоретичного знання відносяться до ідеалізованим, абстрактним об'єктам. Подібні об'єкти неможливо піддати безпосередній експериментальній перевірці. Емпіричні знання отримують в результаті застосування емпіричних методів пізнання - спостереження, вимірювання, експерименту. Це знання про видимі взаємозв'язки між окремими подіями і фактами в предметної області. Воно, як правило, констатує якісні та кількісні характеристики об'єктів і явищ. Емпіричні закони часто носять імовірнісний характер і не є строгими. Позанаукові знання можуть бути різними. Паранормальні знання-знання несумісні з наявним гносеологічним стандартом. Широкий клас паранаукового (пара від грец. - близько, при) знання включає в себе вчення або роздуми про феномени, пояснення яких не є переконливим з точки зору критеріїв науковості. Лженаучние знання - свідомо експлуатуючі домисли і забобони. Як симптоми лженауки виділяють малограмотний пафос, принципову нетерпимість до спростовує доводам, а також претензійність. Лженаучние знання співіснують з науковими знаннями. Особистісні (неявні, приховані) знання - це знання людей, отримані з практики і досвіду. Формалізовані (явні) знання - знання містяться в документах, на компакт дисках, в персональних комп'ютерах, в Інтернеті, в базах знань, в експертних системах. Формалізовані знання об'ектівізіруются знаковими засобами мови, охоплюють ті знання, про які ми знаємо, їх можна записати, повідомити іншим. Класифікація моделей подання знаньДля зберігання даних використовуються бази даних (для них характерні великий обсяг і відносно невелика питома вартість інформації), для зберігання знань - бази знань (невеликого обсягу, але виключно дорогі інформаційні масиви). База знань - основа будь-якої інтелектуальної системи, де знання описані на деякій мові представлення знань, наближеному до природного. Сьогодні знання придбали чисто декларативну форму, т. Е. Знаннями вважаються пропозиції, записані на мовах подання знань, наближених до природної мови і зрозумілих неспеціалістам. Сукупність знань потрібних для прийняття рішень, прийнято називати предметною областю або знаннями про предметну область. У будь-якій предметній області є свої поняття і зв'язки між ними, своя термінологія, свої закони, що зв'язують між собою об'єкти даних предметної області, свої процеси і події. Крім того, кожна предметна область має свої методи вирішення завдань. Вирішуючи завдання такого виду на ЕОМ використовують інформаційні системи, ядром яких є база знань, яка містить основні характеристики предметних областей. Бази знань базуються на моделях представлення знань, подібно баз даних, які засновані на моделях представлення даних (ієрархічної, мережевої, реляційної, постреляціонной і т.д.) При поданні знань в пам'яті інтелектуальної системи традиційні мови, засновані на чисельному поданні даних, є неефективними. Для цього використовуються спеціальні мови представлення знань, засновані на символьному поданні даних. Вони діляться на типи за формальними моделям представлення знань. Найбільш часто використовується на практиці класифікація моделей подання знань, наведена на рис. 6, де моделі представлення знанні діляться на детерміновані (жорсткі) і м'які. Детерменірованние моделі включають в себе фрейми, логіко-алгебраїчні моделі, семантичні мережі і продукційні моделі. М'які моделі включають в себе нечіткі системи, нейронні мережі, еволюційні моделі, гібридні системи. З моделюванням знань безпосередньо пов'язана проблема вибору мови уявлення. З метою класифікації моделей уявлення знань виділяється дев'ять ключових вимог до моделей знань: 1) спільність (універсальність); 2) наочність представлення знань; 3) однорідність; 4) реалізація в моделі властивості активності знань; 5) відкритість; 6) можливість відображення структурних відносин об'єктів предметної області; 7) наявність механізму «проектування» знань на систему семантичних шкал; 8) можливість оперування нечіткими знаннями; 9) використання багаторівневих уявлень (дані, моделі, метамоделі, метаметамоделі і т. Д.).
Мал. 6. Моделі представлення знань Моделі подання знань не задовольняють повністю ці вимоги, чим і пояснюється їх різноманіття і активний розвиток цього напрямку. Логіко -алгебраіческіе моделі подання знань У логічних моделях знання представляються у вигляді сукупності правильно побудованих формул будь-якої формальної системи, яка задається четвіркою S = , де Т- безліч базових (термінальних) елементів, з яких формуються всі вирази; Р - безліч синтаксичних правил, що визначають синтаксично правильні вирази з термінальних елементів формальної системи; А - безліч аксіом формальної системи, відповідних синтаксично правильним виразами, які в рамках даної ФС апріорно вважаються істинними; R -Кінцеве безліч відносин {r 1, r 2,..., r n} між формулами, званими правилами виведення, що дозволяють отримувати з одних синтаксично правильних виразів інші. Для будь-якого r i існує ціле позитивне число j, таке, що для кожного безлічі, що складається з j формул, і для кожної формули F ефективно вирішується питання про те, чи знаходяться ці j-формули щодо r i з формулою F. Якщо r i виконується, то F називають безпосереднім наслідком F-формул за правилом r i. Наслідком (висновком) формули в теорії S називається така послідовність правил, що для будь-якого з них представлена формула є або аксіомою теорії S, або безпосереднім наслідком. Найпростішою логічною моделлю є числення висловів, яке представляє собою один з початкових розділів математичної логіки, що є основою для побудови більш складних формализмов. У практичному плані обчислення висловлювань застосовується в ряді предметних областях (зокрема, при проектуванні цифрових електронних схем). Розвиток логіки висловлювань знайшло відображення в численні предикатів першого порядку. Під обчисленням предикатів розуміється формальний мову для подання відносин в деякій предметній області. Основна перевага числення предикатів - добре зрозумілий механізм математичного виведення, який може бути безпосередньо запрограмований. Предикатом називають пропозицію, яка приймає тільки два значення: "істина" або "брехня". Для позначення предикатів застосовуються логічні зв'язки між висловлюваннями: ¬ - ні, Таким чином, логіка предикатів оперує логічними зв'язками між висловлюваннями, наприклад, вона вирішує питання: чи можна на основі висловлювання A отримати висловлювання B і т.д. Допустимі висловлювання на обчисленні предикатів називаються правильно побудованими формулами, що складаються з атомних формул. Атомні формули складаються з предикатів і термів, що розділяються круглими, квадратними і фігурними дужками. Предикатні символи - це в основному дієслівна форма (наприклад: ПИСАТИ, ВЧИТИ, ПЕРЕДАТИ), але не тільки дієслівна форма, а форма прикметників, прислівників (наприклад: ЧЕРВОНИЙ, ЗНАЧЕННЯ, ЖОВТИЙ). Предикатні символи і константи, як правило, позначатися великими символами, функціональні символи і змінні - малими. В абстрактних прикладах вони позначаються латинськими літерами f, g, h. У пропозиціях предикатной форми важливі відносини і елементи. Визначаючи відносини, ми визначаємо значимість елементів вираження. Елементи можуть бути предикатами і термами. Якщо існує деяка предметна область, то предикати визначають відносини в цій предметній області, константи - елементи цієї предметної області, функціональний символ - функцію. Розглянемо деякі приклади. Вислів "у кожної людини є батько" можна записати:  x x  y (ЛЮДИНА (x) y (ЛЮДИНА (x)  БАТЬКО (y, x)) БАТЬКО (y, x))
Вираз "Антон володіє червоною машиною" записується, наприклад, так: x (ВОЛОДІЄ (АНТОН, x) МАШИНА (x) 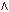 ЧЕРВОНИЙ (x)) ЧЕРВОНИЙ (x))
Подання знань в рамках логіки предикатів є основою напрямки ІІ, що називається логічним програмуванням []. Методи логічного програмування в даний час широко використовуються на практиці при створенні ІІ в ряді предметних областей. Позитивними рисами логічних моделей знань в цілому є: - високий рівень формалізації, що забезпечує можливість реалізації системи формально точних визначень і висновків; - узгодженість знань як єдиного цілого, що полегшує вирішення проблем верифікації БЗ, оцінки незалежності та повноти системи аксіом і т. Д .; - єдині засоби опису як знань про предметну область, так і способів вирішення завдань в цій предметній області, що дозволяє будь-яке завдання звести до пошуку логічного виведення деякої формули в тій чи іншій формальної системи. Однак така однаковість тягне за собою основний недолік моделі - складність використання в процесі логічного висновку евристик, що відображають специфіку предметної області.До інших недоліків логічної моделі відносять: - "монотонність"; - "комбінаторний вибух"; - слабкість структурованості описів. Продукційні моделі подання знань Продукционная модель або модель, заснована на правилах, дозволяє уявити знання у вигляді пропозицій типу "Якщо (умова), то (дія)". Під "умовою" (антецедентом) розуміється деякий пропозицію-зразок, за яким здійснюється пошук в базі знань, а під "дією" (консеквентом) - дії, що виконуються при успішному результаті пошуку (вони можуть бути проміжними, які виступають далі як умови, і термінальними або цільовими, завершальними роботу системи). Продукционная модель в чистому вигляді не має механізму виходу з тупикових станів в процесі пошуку. Вона продовжує працювати, поки не будуть вичерпані всі допустимі продукції. Практичні реалізації продукційних систем містять механізми повернення в попередній стан для управління алгоритмом пошуку. Розглянемо приклад використання продукційних правил. П1: Якщо "відпочинок - влітку" і "людина - активний", то "їхати в гори". П2: Якщо "любить сонце", то "відпочинок влітку". Припустимо, в систему надійшли дані - "людина активна" і "любить сонце". Прямий висновок - виходячи з даних, отримати відповідь. 1-й прохід. Крок 1. Пробуємо П1, не працює (не вистачає даних "відпочинок - влітку"). Крок 2. Пробуємо П2, працює, в базу надходить факт "відпочинок - влітку". 2-й прохід. Крок 3. Пробуємо П1, працює, активується мета "їхати в гори", яка і виступає як порада, яку дає ЕС. Зворотний висновок - підтвердити обрану мета за допомогою наявних правил і даних. 1-й прохід. Крок 1. Мета - "їхати в гори": пробуємо П1 - даних "відпочинок - влітку" немає, вони стають новою метою, і шукається правило, де вона в правій частині. Крок 2. Мета "відпочинок - влітку": правило П2 підтверджує мету і активує її. 2-й прохід. Крок 3. Пробуємо П1, підтверджується шукана мета.Основні переваги продукційних систем: - простота і гнучкість виділення знань; - відділення знань від програми пошуку; - модульність продукційних правил (правила не можуть "викликати" інші правила); - можливість евристичного управління пошуком; - можливість трасування "ланцюжка міркувань"; - незалежність від вибору мови програмування; - продукційні правила є правдоподібною моделлю рішення задачі людиною. Є велика кількість програмних засобів, що реалізують продукційний підхід (наприклад, мови високого рівня CLIPS і OPS 5; "оболонки" або "порожні" ЕС - EXSYS Professional і Карра, інструментальні КЕЕ, ARTS, PIES, а також промислових ЕС на його основі. семантичні мережі Семантична мережа - це орієнтований граф, вершини якого - поняття, а дуги - відносини між ними. Термін "семантична" означає "смислова", а сама семантика - це наука, що встановлює відносини між символами і об'єктами, які вони позначають, т. Е. Наука, яка визначає зміст знаків. Модель на основі семантичних мереж була запропонована американським психологом Куілліаном. Як понять зазвичай виступають абстрактні або конкретні об'єкти, а відносини це зв'язки типу: "це" ( "АКО - A-Kind-Of," is "або" елемент класу ")," має частиною "(" has part "), "належить", "любить". Можна запропонувати кілька класифікацій семантичних мереж, пов'язаних з типами відносин між поняттями. За кількістю типів відносин: - однорідні (з єдиним типом відносин); - неоднорідні (з різними типами відносин). За типами відносин: - бінарні (в яких відносини пов'язують два об'єкти); - N-арні (в яких є спеціальні відносини, що зв'язують більше двох понять). Найбільш часто в семантичних мережах використовуються наступні відносини: - елемент класу (троянда це квітка); - атрибутивні зв'язку / мати властивість (пам'ять має властивість - обсяг); - значення властивості (колір має значення - жовтий); - приклад елемента класу (троянда, наприклад - чайна); - зв'язку типу "частина-ціле" (велосипед включає кермо); - функціональні зв'язку (визначені зазвичай дієсловами "виробляє", "впливає" ...); - кількісні (більше, менше, дорівнює ...); - просторові (далеко від, близько від, за, під, над ...); - тимчасові (раніше, пізніше, протягом ...); - логічні зв'язки (і, або, не) і ін. Мінімальний склад відносин в семантичної мережі такий: - елемент класу або АКО; - атрибутивні зв'язку / мати властивість; - значення властивості. Недоліком цієї моделі є складність організації процедури організації виведення. Приклад семантичної мережі для пропозиції типу "Постачальник здійснив поставку виробів для клієнта до 1 червня 2010 року в кількості 10 000 штук" представлений на рис. 7.
Рис.7. Приклад семантичної мережі. фрейми Фрейм - це мінімально можливе опис сутності якої-небудь події, ситуації, процесу або об'єкта. В історичному плані розвиток фреймовой моделі пов'язано з теорією фреймів М. Мінського, визначальною спосіб формалізації знань, який використовується при вирішенні задач розпізнавання образів (сцен) і розуміння мови. «Відправним моментом для даної теорії служить той факт, що людина, намагаючись пізнати нову для себе ситуацію або по-новому поглянути на вже звичні речі, вибирає зі своєї пам'яті деяку структуру даних (образ), звану нами фреймом, з таким розрахунком, щоб шляхом зміни в ній окремих деталей зробити її придатною для розуміння більш широкого класу явищ або процесів ». Іншими словами, фрейм - це форма опису знань, що окреслює рамки розглянутого (в поточній ситуації при вирішенні даного завдання) фрагмента предметної області. Модель фрейма є досить універсальною, оскільки дозволяє відобразити все різноманіття знань про світ через: - фрейми - структури, для позначення об'єктів і понять (позика, застава, вексель); - фрейми - ролі (менеджер, касир, клієнт); - фрейми - сценарії (банкрутство, збори акціонерів, святкування іменин); - фрейми - ситуації (тривога, аварія, робочий режим пристрою) і ін. Розрізняють фрейми-зразки або прототипи і фрейми-екземпляри, які створюються для відображення реальних фактичних ситуацій на основі даних, що надходять. Фрейм має ім'я (назва) та складається з слотів. Традиційно структура фрейму може бути представлена як список властивостей: (Ім'я фрейма: (ім'я 1-го слота: значення 1-го слота), (ім'я 2-го слота: значення 2-го слота), ................ (ім'я N-г o слота: значення N-го слота)). Ту ж запис можна представити у вигляді таблиці (див. Табл. 1), доповнивши її двома стовпцями. Таблиця 1 . структура фрейму
У таблиці додаткові стовпці (3-й і 4-й) призначені для опису способу отримання слотом його значення і можливого приєднання до того чи іншого слоту спеціальних процедур, що допускається в теорії фреймів. Як значення слота може виступати ім'я іншої фрейма, так утворюються мережі фреймів. Широко відомі такі фрейми-орієнтовані експертні системи, як ANALYST, МОДІС. Тест по темі «Представлення знань» 1. Що розуміється під поданням знань? a) це кодування інформації, на якому - або формальній мові; b) знання представлені в програмі на мові С ++; c) знання представлені в підручниках з математики; d) моделювання знань фахівців - експертів. 2. Які визначення представлені нижче не є моделями подання знань? a) продукційні моделі; b) фрейми; c) імітаційні моделі; d) семантичні мережі; e) формально - логічні моделі. 3. Що являють собою семантична мережу ?: a) мережевий графік, вершини якого - терміни виконання робіт; b) це нейронна мережа, що складається з нейронів; c) орієнтований граф, вершини якого - поняття, а дуги - відносини між ними. 4. Який з основних типів відносин семантичної мережі, представлених нижче, може бути названа як АКО (A - Kind - Of)? a) це; b) елемент класу; c) має частиною; d) належить; e) функціональний зв'язок. 5. Чим відрізняються семантичні мережі і фрейми? a) Елемент моделі складається з безлічі незаповнених значень деяких атрибутів, іменованих «слотами»; b) спадкування за AKO- зв'язків; c) елемент моделі - структура, що використовується для позначення об'єктів і понять. 6. Що об'єднує семантичні мережі і фрейми? a) організація процедури виведення; b) успадкування властивостей; c) безлічі незаповнених значень деяких атрибутів, іменованих «слотами»; d) структури, що використовуються для позначення об'єктів і понять. 7. Які з виразів, представлених нижче, є структурною частиною фрейму ?: a) значення N- го слота; b) шаблон; c) примітивні типи даних. 8. На якому формалізмі НЕ засновані логічні моделі ?: a) числення висловів; b) пропозіціональная логіка; c) силогізми Аристотеля; d) правильно побудовані формули; e) нечіткі системи (fuzzy set). Література по темі «Представлення знань» 1. Барсегян А.А., Купріянов М.С., Степаненко В.В., Холод І.І. Методи і моделі аналізу даних: OLAP і Data Mining. - СПб .: БХВ-Петербург, 2004. - 336 с. 2. Гаврилова Т.А., Хорошевський В.Ф. Бази знань інтелектуальних систем. СПб .: Пітер, 2001. с. 384. 3. Рассел С., Норвіг П. Штучний інтелект: сучасний підхід, 2-е вид. - М .: Вільямс, 2006. - с. 1408. §2. Нейронні мережі Так як основне завдання штучного інтелекту - моделювання міркувань, а природне «пристрій здатне думати» - це мозок, то очевидною завданням є створення «штучного мозку» «за образом і подобою» людського. Дослідженням цього питання стали займатися в рамках напрямку штучного інтелекту нейрокібернетика. Пристрої мозку вивчають такі науки як психологія, нейрофізіологія, нейробиология, що володіють достатнім обсягом знань. Основною ідеєю нейрокібернетики стало відтворення «в залізі» клітини мозку - нейрони. Нейрони - спеціалізовані клітини, здатні приймати, обробляти, кодувати, передавати і зберігати інформацію, організовувати реакції на подразнення, встановлювати контакти з іншими нейронами, клітинами органів. Унікальними особливостями нейрона є здатність генерувати електричні розряди і передавати інформацію за допомогою спеціалізованих закінчень - синапсів. Число нейронів мозку людини наближається до 10 11.На одному нейроні може бути до 10 000 синапсів. Якщо тільки ці елементи вважати осередками зберігання інформації, то можна прийти до висновку, що нервова система може зберігати 10 19 од. інформації, т. е. здатна вмістити практично все знання, накопичені людством. На рис. 8. приведена схема будови "типового" нейрона.
Мал. 8. Загальна схема будови біологічного нейрона. Тіло клітини містить безліч розгалужених відростків двох типів. Відростки першого типу, звані дендритами за їх схожість з кроною розлогого дерева, служать в якості вхідних каналів для нервових імпульсів від інших нейронів. Ці імпульси надходять в сому або тіло клітини розміром від 3 до 100 мікрон, викликаючи її специфічне збудження, яке потім поширюється по вивідній відростка другого типу - аксону. Довжина аксонів зазвичай помітно перевершує розміри дентрітов, в окремих випадках досягаючи десятків сантиметрів і навіть метрів. Нейрон може перебувати в 2 станах: збудженому або збудженому. 1943 рік став роком народження теорії штучних нейронних мереж. Дж. Маккалок і У. Пітт запропонували модель формального нейрона (рис. 9) і описали основні принципи побудови нейронних мереж. Синапси нейрона - місця контактів нервових волокон - відповідно до цієї моделі, передають сигнали, визначаючи силу впливу сигналу з цього входу на вихідний сигнал, що надходить на аксон. Для цього кожному входу ставиться у відповідність ваговий коефіцієнт w i. Дендрити отримують вхідний сигнал, представлений вектором x i. Потім нейрон обробляє надійшов сигнал, виробляючи зважене підсумовування і нелінійне перетворення, використовуючи для цього активаційну функцію (функції активації можуть бути різними, найбільш поширені лінійна, порогова і сігмойда), аргументом якої буде результат підсумовування мінус граничне значення. Це значення визначає рівень сигналу, на який нейрон буде реагувати.
Мал. 9. Модель формального нейрона Головною властивістю біологічного нейрона є його здатність до навчання, його універсальність, здатність вирішувати різні завдання. Описана вище модель не здатна до цього. Навченою вона стала лише в 1949 році завдяки Д.Хеббу (D. Hebb), який, спираючись на фізіологічні та психологічні дослідження, висунув гіпотезу про навченості біологічних нейронів. Його метод навчання став відправною точкою для алгоритмів навчання нейронних мереж без вчителя. Уже через рік після цього в 1957 році в світовому науковому світі стався другий за значимістю в історії нейронних мереж подія: американський фізіолог Ф. Розенблатт розробив модель зорового сприйняття і розпізнавання - перцептрон (perceptron), а потім і побудував перший нейрокомп'ютер Марк-1. Нейронні мережі була прості, зрозумілі і багатообіцяючі. Складні процеси мислення, здавалося, були готові розкритися перед людиною, для їх опису були потрібні лише елементарні математичні операції: додавання, множення і лінійна функція. На персептрон, а потім і багатошаровий персептрон покладалися великі надії, тому бурхливий ентузіазм, з яким він був прийнятий, досить швидко змінився жорсткою критикою. У 1969 році вийшла в світ книга «Персептрони» М. Мінського і С. паперті, яка ознаменувала закінчення першого етапу в історії нейронних мереж. У цій книзі було проведено аналіз можливостей одношарових нейронних мереж та їх обмежень. Обмеження, виявлені Мінським, були характерні одношаровим нейронних мереж, але не багатошаровим нейронних мереж, яким була властива інша проблема - їх навчання. Запропонований 1986 році Д. Румельхардом алгоритм зворотного поширення помилки став одним з провідних чинників, що породили сучасний нейросетевой бум, тому що був ефективним способом навчання нейронної мережі досить довільної структури. Нейронні мережі можуть реалізовуватися як програмно, так і апаратно. Поступово напрямок нейрокібернетика перетворилося в нейрокомпьютинг, шосте покоління комп'ютерів, що базується на нейронних мережах, має свої переваги і недоліки. Порівняльний аналіз машини фон Неймана, ідеї якої втілені в перших 4 поколіннях, і біологічної нейронної системи, що є прообразом нейрокомп'ютера, представлений в таблиці 1. Таблиця 2. Порівняння машини фон Неймана з біологічної нейронної системою.
Класифікація штучних нейронних мережЗа топології (рис. 10, рис. 11): - повнозв'язні (кожен нейрон пов'язаний з усіма іншими нейронами, в тому числі і сам з собою); - багатошарові (нейрони розташовуються шарами і кожен нейрон наступного шару пов'язаний з усіма нейронами поточного шару).
Мал. 10. Повнозв'язна нейронна мережа Рис. 11. Шарувата нейронна мережа За організації навчання: - з учителем (нейронну мережу навчають, подаючи на вхід значення навчальної вибірки і надаючи необхідні вихідні значення); - без вчителя (на входи нейронної мережі подають безліч об'єктів і нейронна мережа сама ділить їх на кластери або класи). За типами структур (рис. 12): - нейрони з одним типом функції активації (всі нейрони мережі мають одну функцію активації f (x), наприклад, лінійну); - нейрони з декількома типами функцій активації (нейрони мережі мають різні функції активації).
Рис.12 Активаційні функції За типом зв'язків: - прямого поширення (без зворотних зв'язків між нейронами, до таких мереж відносяться одношаровий і багатошаровий персептрони, мережа радіальних базисних функцій); - рекурентні (зі зворотним зв'язком, від виходів нейронів до входів, до таких мереж відносяться змагальні мережі і мережу Хопфілда). За типом сигналу: - бінарні (на входи подаються тільки нулі і одиниці); - аналогові (на входи нейронів подаються значення безперервних функцій). Одношарові штучні нейронні мережіОдин нейрон здатний виконувати найпростіші процедури розпізнавання, але тільки з'єднання декількох нейронів здатне вирішити практично корисну завдання. Найпростіша мережа (рис. 13) складається з групи нейронів, що утворюють шар).
Мал. 13.Однослойная нейронна мережа Навчання за дельта-правилом Дельта-правило є узагальненням алгоритму навчання персептрона. Дельта-правило працює тільки з безперервними, диференційовними функціями в режимі навчання з учителем (supervised learning). Помилка, що обчислюється в процесі навчання мережі, - це функція, що характеризує якість навчання даної мережі, тому процес навчання нейронної мережі можна уявити як процес мінімізації функції помилки. Напрямок зміни значення функції можна встановити, обчисливши похідну для функції одного змінного або градієнт для функції багатьох змінних. При мінімізації значення функції багатьох змінних менше значення необхідно шукати в напрямку антіградіента. В даному алгоритмі навчання початкові ваги можуть бути будь-якими. Процес навчання можна вважати завершеним, якщо досягнута якась заздалегідь встановлена мінімальна помилка або алгоритм пропрацював умовлене кількість разів. Алгоритм навчання по дельта-правилом: 1 крок: ініціалізація матриці ваг (і порогів, у разі використання порогової функції активації) випадковим чином. 2 крок: пред'явлення нейронної мережі способу (на вхід подаються значення з навчальної вибірки - вектор Х), береться відповідний вихід (вектор D). 3 крок: обчислення вихідних значень нейронної мережі (вектор Y). 4 крок: обчислення для кожного нейрона величини розбіжності реального результату з бажаним.
де d i - бажане вихідне значення на i-нейроні, y i - реальне значення на i-нейроні. 5 крок: зміна ваг (і порогів при використанні порогової функції) за формулами:
де t-номер поточної ітерації циклу навчання, 6 крок: перевірка умови продовження навчання (обчислення значення помилки і / або перевірка заданого кількості ітерацій). Якщо навчання не завершено, то 2 крок, інакше закінчуємо навчання. Багатошарові нейронні мережіОдношарові нейронні мережі мають свої обмеження, на які вказав Мінський, багатошарові мережі вільні від них.Вони володіють великими обчислювальними можливостями. Хоча створені мережі всіх конфігурацій, які тільки можна собі уявити, послойная організація нейронів копіює шаруваті структури певних відділів мозку. Багатошарові мережі утворюються каскадами шарів. Вихід одного шару є входом для наступного шару, така організація мережі утворює багатошарову нейронну мережу з прямим розповсюдженням (рис. 14).
Мал. 14. Багатошарова нейронна мережа прямого поширення Багатошарова мережа може містити довільну кількість шарів (K), кожен шар складається з декількох нейронів, число яких також може бути довільно (Н k - кількість нейронів в шарі), кількість входів n, кількість виходів H = H K - числу нейронів у вихідному ( останньому) шарі. Шари між першим і останнім називаються проміжними або прихованими. Ваги в такій мережі мають три індексу i- номер нейрона наступного шару, для якого зв'язок вхідні, j - номер входу або нейрона поточного шару, для якого зв'язок вихідна, k - номер поточного шару в нейронної мережі (для входів, вектора X, k = 0). Навчання методом зворотного поширення помилки Навчання алгоритмом зворотного поширення помилки передбачає два проходи по всім верствам мережі: прямого і зворотного. При прямому проході вхідний вектор подається на вхідний прошарок нейронної мережі, після чого поширяться по мережі від шару до шару. В результаті генерується набір вихідних сигналів, який і є фактичною реакцією мережі на даний вхідний образ. Під час прямого проходу все синаптичні ваги мережі фіксовані. Під час зворотного проходу все синаптичні ваги налаштовуються відповідно до правила корекції помилок, а саме: фактичний вихід мережі віднімається з бажаного, в результаті чого формується сигнал помилки. Цей сигнал згодом поширюється по мережі в напрямку, протилежному напрямку синаптичних зв'язків. Звідси і назва - алгоритм зворотного поширення помилки. Синаптичні ваги налаштовуються з метою максимального наближення вихідного сигналу мережі до бажаного. Алгоритм навчання по дельта-правилом: 1 крок: ініціалізація матриць ваг випадковим чином (в циклах). 2 крок: пред'явлення нейронної мережі способу (на вхід подаються значення з навчальної вибірки - вектор Х) і береться відповідний вихід (вектор D). 3 крок (прямий прохід): обчислення в циклах виходів всіх верств і отримання вихідних значень нейронної мережі (вектор Y).
де 4 крок (зворотний прохід): зміна ваг в циклах за формулами:
для останнього (вихідного) шару,
для проміжних шарів, де t-номер поточної ітерації циклу навчання (номер епохи),
5 крок: перевірка умови продовження навчання (обчислення значення помилки і / або перевірка заданого кількості ітерацій). Якщо навчання не завершено, то 2 крок, інакше закінчуємо навчання. Ефективне значення помилка обчислюється таким чином:
де Q - загальна кількість прикладів, H - кількість нейронів у вихідному шарі, d i - бажане вихідне значення на i-нейроні, y i - реальне значення на i-нейроне вихідного шару. Завдання, які вирішуються нейронними мережами1. Класифікація образів. Завдання полягає у визначенні приналежності вхідного образа (наприклад, мовного сигналу або рукописного символу), представленого вектором ознак до одного або декількох попередньо визначеним класам. До відомих додатків відносяться розпізнавання букв, розпізнавання мови, класифікація сигналу електрокардіограми, класифікація клітин крові. 2. Кластеризація / категоризація. При вирішенні задачі кластеризації навчальну множину не має міток класів. Алгоритм кластеризації заснований на подобі образів і поміщає схожі образи в один кластер. Відомі випадки застосування кластеризації для видобутку знань, стиснення даних і дослідження властивостей даних. 3. Апроксимація функцій. Припустимо, що є навчальна вибірка ((x1, y1), (x2, y2) ..., (xn, yn)) (пари даних вхід-вихід), яка генерується невідомою функцією F, спотвореної шумом. Завдання апроксимації полягає в знаходженні невідомої функції F. Апроксимація функцій необхідна при вирішенні численних інженерних і наукових задач моделювання. 4. Передбачення / прогноз. Нехай задані n дискретних відліків {y (t1), y (t2), ..., y (tn)} в послідовні моменти часу t1, t2, ..., tn. Завдання полягає в передбаченні значення y (tn + 1) в наступний момент часу tn + 1. Передбачення / прогноз мають велике значення для прийняття рішень в бізнесі, науці і техніці (передбачення цін на фондовій біржі, прогноз погоди). 5. Оптимізація. Численні проблеми в математиці, статистиці, техніці, науці, медицині та економіці можуть розглядатися як проблеми оптимізації. Завданням алгоритму оптимізації є знаходження такого рішення, яке задовольняє системі обмежень і максимізує або мінімізує цільову функцію. 6. Пам'ять, що адресується за змістом. У традиційних комп'ютерах звернення до пам'яті доступно тільки за допомогою адреси, що не залежить від змісту пам'яті. Більш того, якщо допущена помилка в обчисленні адреси, то може бути знайдена зовсім інша інформація. Асоціативна пам'ять або пам'ять, що адресується за змістом, доступна за вказівкою заданого змісту. Вміст пам'яті може бути викликано навіть по частковому входу або пошкодженому змісті. Асоціативна пам'ять може бути використана в мультимедійних інформаційних базах даних. 7. Управління. Розглянемо динамічну систему, задану сукупністю {u (t), y (t)}, де u (t) - вхідний керуючий вплив, а y (t) - вихід системи в момент часу t. У системах управління з еталонною моделлю метою управління є розрахунок такого вхідного впливу u (t), при якому система діє по бажаної траєкторії, заданої еталонної моделлю. Прикладом є оптимальне управління двигуном. Тест по темі «Нейронні мережі»: 1. Хто розробив перший нейрокомп'ютер? a) У. Маккалок b) М. Мінський c) Ф. Розенблатт d) Немає правильної відповіді 2. Які завдання не вирішують нейронні мережі? a) класифікація b) апроксимація c) пам'ять, що адресується за змістом d) маршрутизація e) управління f) кодування 3. Яку функцію не може вирішити одношарова нейронна мережа? a) логічне «не» b) підсумовування c) логічне «виключає або» d) твір e) логічне «або» 4. Що з нижче перерахованого відноситься до персептрону? a) одношарова нейронна мережа b) нейронна мережа прямого поширення c) багатошарова нейронна мережа d) нейронна мережа із зворотними зв'язками e) створений Ф. Розенблатта f) створений У. Маккалоком і В. Піттом 5. Хто написав книгу «Персепторни»? a) У. Маккалок і В. Пітт b) М. Мінський і С. Паперть c) Ф. Розенблатт 6. Яку нейронну мережу навчають за допомогою дельта-правила? a) одношарову нейронна мережа b) нейронну мережу прямого поширення c) нейронну мережу з зворотними зв'язками d) мережу Хопфілда e) немає правильної відповіді 7. Яку нейронну мережу навчають з алгоритму зворотного поширення помилки? a) Одношарову нейронна мережа b) багатошарову нейронну мережу прямого поширення c) багатошарову нейронну мережу з зворотними зв'язками d) немає правильної відповіді 8. Які з перерахованих мереж є рекурентними? a) персептрон b) мережу Хопфілда c) мережу радіальних базисних функцій d) немає правильної відповіді Література по темі «Нейронні мережі»: 1. Джейн Аніл К., Мао Жіанчанг, Моіуддін До М. Введення в штучні нейронні мережі // Відкриті системи, · 1997 №4, с. 16-24. 2. Заенцев І. В. Нейронні мережі: основні моделі. Навчальний посібник до курсу "Нейронні мережі" для студентів 5 курсу магістратури. Воронеж. 1999. с. 76. 3. Міркес, Е.М. Нейроінформатика: Учеб. посібник для студентів. Красноярськ: ІСЦ КДТУ, 2002 347 с. 4. Нейроінформатика / А.Н.Горбань, В.Л.Дунін-Барковський, А.Н.Кірдін і ін. - Новосибірськ: Наука. Сибірське підприємство РАН, 1998. - 296с. 5. Нейрокомп'ютер. Проект стандарту / Е.М.Міркес - Новосибірськ: Наука, Сибірська видавнича фірма РАН, 1998.. 6. Терехов С. А. Лекції з теорії і додатків штучних нейронних мереж. ВНДІТФ, Снежинськ, 1998. http://alife.narod.ru/lectures/neural/Neu_ch03.htm 7. Уоссермен Ф. нейрокомп'ютерних техніка: Теорія і практика. - Пер. з англ., 1992. - 118 с. §3. еволюційне моделювання Однією з головних характеристик штучного інтелекту як науки є його міждисциплінарність, що дозволяє залучати цікаві ідеї, теорії з інших областей знань, адаптую і використовуючи готові розробки для своїх завдань. Так було з нейронними мережами, з моделюванням міркувань, з комп'ютерною лінгвістикою тощо Багато значущі теорії науки були так чи інакше буде переглянуто через призму штучного інтелекту. Теорія Ч. Дарвіна (1859 г.) стала відправною точкою для ще одного напрямку досліджень - еволюційного моделювання. Основна теза еволюційного моделювання - замінити процес моделювання складного об'єкта моделюванням його еволюції. Він спрямований на застосування механізмів природної еволюції при синтезі складних систем обробки інформації. Дарвін сформулював основний закон розвитку органічного світу, охарактеризувавши його взаємодією трьох наступних факторів: · Спадковість (нащадки зберігають властивості батьків); · Мінливість (нащадки майже завжди не ідентичні); · Природний відбір (виживають найбільш пристосовані). Теорія Дарвіна, доповнена генетичними знаннями, називається синтетичної теорією еволюції. Випадкову появу нових ознак вона пояснила мутаціями - змінами, що виникають в ДНК організмів. Поняття «еволюційне моделювання» сформувалося в роботах Л. Фогеля, А. Оуена, М. Уолша. У 1966 році вийшла їхня спільна книга «Штучний інтелект і еволюційне моделювання». Історія еволюційних обчислень почалася з розробки ряду різних незалежних моделей. Основними з них були генетичні алгоритми і класифікаційні системи Д. Холланда (Holland), опубліковані на початку 60-х років і одержали загальне визнання після виходу в світ книги, що стала класикою в цій області, - "Адаптація в природних і штучних системах" ( " Adaptation in Natural and Artifical Systems ", 1975). У 70-х роках в рамках теорії випадкового пошуку Л.А. Растригина був запропонований ряд алгоритмів, що використовують ідеї бионического поведінки особин. Розвиток цих ідей знайшло відображення в циклі робіт І.Л. Букатовой по еволюційному моделювання. Розвиваючи ідеї М.Л. Цетлін про доцільний і оптимальному поведінці стохастичних автоматів, Ю.І. Неймарк запропонував здійснювати пошук глобального екстремуму на основі колективу незалежних автоматів, що моделюють процеси розвитку та елімінації особин. Незважаючи на різницю в підходах, всі вони базувалися на принципах еволюції. В рамках еволюційного моделювання створювалися і досліджувалися моделі походження молекулярно-генетичних систем обробки інформації, моделі, що характеризують загальні закономірності еволюційних процесів, і проводився аналіз моделей штучної «еволюції» з метою застосування методу еволюційного пошуку до практичних завдань оптимізації. На початку 70-х років лауреат Нобелівської премії М. Ейген зробив вражаючу спробу побудови моделей виникнення в ранній біосфері Землі молекулярно-генетичних систем обробки інформації (в моделі квазівидів розглядається поетапна еволюція популяції інформаційних послідовностей (векторів), компоненти яких беруть невелике число дискретних значень. ). Слідом за Ейген в 1980-му новосибірські вчені В. Ратнером і В.Шаміним була запропонована модель «сайзер» (модель сайзер в найпростішому випадку розглядає систему з трьох типів макромолекул: полінуклеотидних матриці і ферментів трансляції та реплікації, кодованих цієї матрицею, полинуклеотидная матриця - це як би пристрій, в якому зберігається інформація про функціональних одиницях сайзера - ферментах.). С. Кауфман зі співробітниками з Пенсильванського університету досліджує еволюцію автоматів, що складаються із сполучених між собою логічних елементів. Д. Коза розробив метод, що дозволяє удосконалювати реальні технічні системи методами генетичного програмування. При цьому еволюція зачіпає не окремі чисельні параметри, а цілі системи (за допомогою цього методу вдалося заново відкрити 15 запатентованих схемотехнік: підсилювачі, фільтри, контролери і т.д.). Переваги еволюційних обчислень: 1) широка область застосування; 2) можливість проблемно-орієнтованого кодування рішень, підбору початкової популяції, комбінування еволюційних обчислень з нееволюційним алгоритмами, продовження процесу еволюції до тих пір, поки є необхідні ресурси; 3) придатність для пошуку в складному просторі рішень великої розмірності; 4) відсутність обмежень на вид цільової функції; 5) ясність схеми і базових принципів еволюційних обчислень; 6) інтегрованість еволюційних обчислень з іншими некласичними парадигмами штучного інтелекту, такими як штучні нейромережі і нечітка логіка. Недоліки еволюційних обчислень: 1) евристичний характер еволюційних обчислень не гарантує оптимальності отриманого рішення; 2) відносно висока обчислювальна трудомісткість, яка долається за рахунок розпаралелювання на рівні організації еволюційних обчислень і на рівні їх безпосередньої реалізації в обчислювальній системі; 3) відносно невисока ефективність на заключних фазах моделювання еволюції (оператори пошуку в еволюційних алгоритмах не орієнтовані на швидке потрапляння в локальний оптимум); 4) невирішеність питань самоадаптації. До методів еволюційного моделювання відносяться · Метод групового урахування аргументів 1) береться самий останній шар класифікаторів; 2) генерується з них за певними правилами новий шар класифікаторів, які тепер самі стають останнім шаром; 3) відбирається з них F кращих, де F - ширина відбору (селекції); 4) якщо одна з вимог припинення селекції (наступ виродження), перехід на п. 1, інакше кращий класифікатор оголошується шуканим рішенням задачі ідентифікації; · Еволюційний (генетичне) програмування (дані, які закодовані в генотипі, можуть являти собою команди будь-якої віртуальної машини, в найпростішому випадку нічого не змінюється в генетичному алгоритмі, але тоді довжина одержуваної послідовності дій (програми) виходить не відрізняється від початкових, сучасні алгоритми генетичного програмування поширюють генетичні алгоритми для систем зі змінною довжиною генотипу); · Генетичні алгоритми. генетичні алгоритми«Батьком» генетичних алгоритмів по праву вважається Д. Холланд, метод спочатку називався репродуктивним планом Холланда. Надалі генетичні алгоритми розвивалися в роботах учнів Холланда: Д. Голдберга. і К. Де Йонга, - саме в них і закріпилася назва методу. Генетичні алгоритми - це розділ еволюційного моделювання, запозичують методичні прийоми з теоретичних положень генетики. Генетичні алгоритми - адаптивні методи пошуку, які використовуються для вирішення задач функціональної оптимізації. Являють собою свого роду моделі машинного дослідження пошукового простору, побудоване на еволюційної метафорі. Характерні особливості: використання рядків фіксованої довжини для подання генетичної інформації, робота з населенням рядків, використання генетичних операторів для формування майбутніх поколінь. Генетичні алгоритми оперують сукупністю особин (популяцією), які представляють собою рядки, які кодують одне з рішень задачі. Цим метод відрізняється від більшості інших алгоритмів оптимізації, які оперують лише з одним рішенням, покращуючи його. Генетичні алгоритми застосовуються для вирішення наступних завдань: · Оптимізація функцій; · Різноманітні завдання на графах (завдання комівояжера, розфарбування і т.д.); · Налагодження та навчання штучної нейронної мережі; · Завдання компонування; · Складання розкладів; · Ігрові стратегії; · Апроксимація функцій; · Штучне життя; · Біоінформатика. Переваги генетичних алгоритмів: 1) універсальність; 2) висока оглядовість пошуку; 3) немає обмежень на цільову функцію; 4) будь-який спосіб завдання функції. Недоліки генетичних алгоритмів: 1) відносно висока обчислювальна вартість; 2) Квазіоптимальний. Коли треба використовувати генетичний алгоритм: багато параметрів, погана цільова функція, комбінаторні задачі. Коли не треба використовувати генетичний алгоритм: з Адачі добре вирішується традиційними методами, потрібна висока точність рішення. Схема функціонування генетичного алгоритмуЗ біології відомо, що будь-який організм може бути представлений своїм фенотипом, який фактично визначає, чим є об'єкт в реальному світі, і генотипом, який містить всю інформацію про об'єкт на рівні хромосомного набору. При цьому кожен ген, тобто елемент інформації генотипу, має своє відображення в фенотипі. Таким чином, для вирішення завдань необхідно представити кожну ознаку об'єкта в формі, придатній для використання в генетичному алгоритмі. Все подальше функціонування механізмів генетичного алгоритму проводиться на рівні генотипу, дозволяючи обійтися без інформації про внутрішню структуру об'єкта, що й обумовлює його широке застосування в самих різних завданнях. У найбільш часто зустрічається різновиди генетичного алгоритму для подання генотипу об'єкту застосовуються бітові рядки. При цьому кожному атрибуту об'єкта в фенотипі відповідає один ген в генотипі об'єкта. Ген являє собою бітову рядок, найчастіше фіксованої довжини, яка представляє собою значення цієї ознаки. Для кодування ген в бінарній реалізації генетичного алгоритму часто використовують код Грея (див. Приклад в таб.3). Таблиця 3. Приклад фенотипу
Після визначення фенотипу генетичний алгоритм функціонує за наступною схемою дій (рис. 15).
Мал. 15Схема функціонування генетичного алгоритму 1. Формування початкової популяції. 2. Оцінка особин популяції. 3. Відбір (селекція). 4. Схрещування. 5. Мутація. 6. Формування нової популяції. 7. Якщо популяція не зійшлися, то 2, інакше - останов (припинення функціонування генетичного алгоритму). Формування початкової популяції Стандартний генетичний алгоритм починає свою роботу з формування початкової популяції - кінцевого набору допустимих рішень задачі. Ці рішення можуть бути обрані випадковим чином або отримані за допомогою простих наближених алгоритмів. Вибір початкової популяції не має значення для збіжності процесу, проте формування "хорошою" початкової популяції (наприклад, з безлічі локальних оптимумів) може помітно скоротити час досягнення глобального оптимуму. Якщо відсутні припущення про місцезнаходження глобального оптимуму, то індивіди з початкової популяції бажано розподілити рівномірно по всьому простору пошуку рішення. Популяція ініціюється в початковий момент часу t = 0 і складається з k особин, кожна з яких представляє можливе рішення даної проблеми. Особина представляє собою одну або кілька хромосом (зазвичай одну). Хромосома складається з ген, - тобто це бітова рядок (хромосоми не обмежені бінарним представленням, є реалізації генетичного алгоритму, побудовані на векторах дійсних чисел). Гени розташовуються в різних позиціях хромосоми, і приймають значення, звані алелями. Оцінка особин популяції Для вирішення завдання за допомогою генетичного алгоритму необхідно задати міру якості для кожного індивіда в просторі пошуку. Для цієї мети використовується функція пристосованості (fitness function). Функція пристосованості повинна приймати невід'ємні значення на обмеженій області визначення, при цьому абсолютно не потрібні безперервність і дифференцируемость, значення цієї функції визначає, наскільки добре підходить особина для вирішення завдання. У завданнях максимізації цільова функція часто сама виступає в якості функції пристосованості, для задач мінімізації цільову функцію слід інвертувати.Якщо можна вирішити завдання має обмеження, виконання яких неможливо контролювати алгоритмічно, то функція пристосованості, як правило, включає також штрафи за невиконання обмежень (вони зменшують її значення). Відбір (селекція) На кожному кроці еволюції за допомогою імовірнісного оператора селекції (відбору) вибираються два рішення-батька для їх подальшого схрещування. Серед операторів селекції найбільш поширеними є два імовірнісних оператора пропорційної і турнірній селекції. У деяких випадках також застосовується відбір урізанням. Пропорційний відбір (Proportional selection) Кожної особини призначає ймовірність Ps (i), що дорівнює відношенню її пристосованості до сумарної пристосованості популяції. Потім відбувається відбір (із заміщенням) усіх n особин для подальшої генетичної обробки, відповідно до величини P s (i). Найпростіший пропорційний відбір - рулетка - відбирає особин за допомогою n «запусків» рулетки. Колесо рулетки містить по одному сектору для кожного члена популяції. Розмір i-ого сектора пропорційний відповідає величині P s (i). При такому відборі члени популяції з більш високою пристосованістю з більшою ймовірністю будуть частіше вибиратися, ніж особини з низькою пристосованістю. турнірний відбір Турнірний відбір реалізується в такий спосіб: з популяції, що містить m особин, вибирається випадковим чином t особин і найбільш пристосована особина записується в проміжний масив (між обраними особами проводиться турнір). Ця операція повторюється m раз. Рядки в отриманому проміжному масиві потім використовуються для схрещування (випадковим чином). Розмір групи рядків, що відбираються для турніру, часто дорівнює 2. У цьому випадку говорять про довічним / парному турнірі. відбір урізанням Дана стратегія використовує відсортовану по спадаючій популяцію. Число особин для схрещування вибирається відповідно до порогом TÎ [0; 1]. Поріг визначає, яка частка особин, починаючи з найпершої (самої пристосованої), братиме участь у відборі. В принципі, поріг можна задати і рівним 1, тоді все особини поточної популяції будуть допущені до відбору. Серед особин, допущених до схрещування випадковим чином m / 2 раз, вибираються батьківські пари, нащадки яких утворюють нову популяцію. рангові відбір Цей вид відбір має на увазі наступне: для кожної особини її ймовірність потрапити в проміжну популяцію пропорційна її порядковому номеру в відсортованої по зростанню пристосованості популяції. Такий вид відбору не залежить від середньої пристосованості популяції. елітний відбір Елітні методи відбору гарантують, що при відборі обов'язково будуть виживати кращий або кращі члени популяції. Найбільш поширена процедура обов'язкового збереження тільки однієї кращої особини, якщо вона не пройшла, як інші, через процес відбору, кросовера і мутації. Елітизм може бути впроваджений практично в будь-який стандартний метод відбору. Використання елітизму дозволяє не втратити гарне проміжне рішення, але в той же час з-за цього алгоритм може "застрягти" в локальному екстремуму. У більшості випадків елітизм не шкодить пошуку рішення, і головне - це надати алгоритму можливість аналізувати різні хромосоми з простору пошуку. схрещування Як відомо, в теорії еволюції важливу роль відіграє те, яким чином ознаки батьків передаються нащадкам. У генетичних алгоритмах за передачу ознак батьків нащадкам відповідає оператор, який називається схрещування (його також називають кросовер або кросинговер). Цей оператор визначає передачу ознак батьків нащадкам, до них застосовується імовірнісний оператор схрещування, який будує на їх основі нові (1 або 2) рішення-нащадка. Відібрані особи піддаються кросоверу (іноді званого рекомбінацією) із заданою вірогідністю P c. Якщо кожна пара батьків породжує двох нащадків, для відтворення популяції необхідно схрестити m / 2 пари. Для кожної пари з імовірністю P c застосовується кросовер. Відповідно, з імовірністю 1-P c кросовер не відбувається - і тоді незмінені особини переходять на наступну стадію (мутації). Існує велика кількість різновидів оператора схрещування. Найпростіший одноточковий кросовер працює наступним чином. Спочатку випадковим чином вибирається одна з можливих точок розриву. (Точка розриву - ділянка між сусідніми бітами в рядку.) Обидві батьківські структури розриваються на два сегменти по цій точці. Потім відповідні сегменти різних батьків склеюються і виходять два генотипу нащадків. Батько 1 1 0 0 1 0 1 1 | 0 1 0 0 1 Батько 2 0 1 0 0 0 1 1 | 0 0 у середньому 1 1 + 1 Нащадок 1 1 0 0 1 0 1 1 | 0 0 у середньому 1 1 + 1 Нащадок 2 0 1 0 0 0 1 1 | 0 1 0 0 1 В даний час дослідники ГА пропонують багато інших операторів схрещування. Двоточковий кросовер (і рівномірний кросовер - цілком гідні альтернативи одноточечного оператору. В двоточковому кросовері обираються дві точки розриву, і батьківські хромосоми обмінюються сегментом, який знаходиться між двома цими точками. У рівномірному кросовері кожен біт першого нащадка випадковим чином успадковується від одного з батьків; другого нащадку дістається біт другого з батьків. мутація Наступний генетичний оператор призначений для того, щоб підтримувати різноманітність особин з популяції, - це оператор мутації. Після того, як закінчиться стадія кросовера, нащадки можуть піддаватися випадковим модифікаціям. У найпростішому випадку в кожній хромосомі, яка піддається мутації, кожен біт з імовірністю P m змінюється на протилежний (це так звана одноточковий мутація). Особина до мутації: 1 0 0 1 0 1 1 0 0 1 1 1 Особина після мутації: 1 0 0 1 0 1 0 0 0 1 1 1 Складнішою різновидом мутації є оператори інверсії і транслокації. Інверсія - це перестановка генів в зворотному порядку всередині навмання вибраної ділянки хромосоми. Особина до інверсії: 1 0 0 1 1 1 1 0 0 1 1 1 Особина після інверсії: 1 0 0 1 0 0 1 1 1 1 1 1 Транслокация - це перенесення якої-небудь ділянки хромосоми в інший сегмент цієї ж хромосоми. Особина до транслокації: 1 0 0 1 1 1 1 0 0 1 1 1 Особина після транслокації: 1 1 1 0 0 0 1 1 0 1 1 + 1 Всі перераховані генетичні оператори (одноточковий і многоточечний кросовер, одноточковий мутація, інверсія, транслокація) мають схожі біологічні аналоги. Формування нового покоління Після схрещування і мутації особин необхідно вирішити проблему: які з нових особин увійдуть в наступне покоління, а які - ні, і що робити з їхніми предками. Є два найпоширеніші способи. 1. Нові особини (нащадки) займають місця своїх батьків. Після цього настає наступний етап, в якому нащадки оцінюються, відбираються, дають потомство і поступаються місцем своїм "дітям". 2. Наступна популяція включає в себе як батьків, так і їх нащадків. У другому випадку необхідно додатково визначити, які з особин батьків і нащадків потраплять в нове покоління. У найпростішому випадку, в нього після кожного схрещування включаються дві кращих особини з четвірки батьків та їхніх нащадків. Більш ефективним є механізм витіснення, який реалізується таким чином, що прагне видаляти «схожі» хромосоми з популяції і залишати відрізняються. критерії зупинки Інший важливий момент функціонування алгоритму - визначення критеріїв зупинки. Взагалі кажучи, такий процес еволюції може тривати до нескінченності. Зазвичай в якості них застосовуються або обмеження на максимальне число епох функціонування алгоритму, або визначення його збіжності, зазвичай шляхом порівнювання пристосованості популяції на кількох епохах і зупинки при стабілізації цього параметра. Сходженням називається такий стан популяції, коли всі рядки популяції майже однакові і знаходяться в області деякого екстремуму (рис. 16).
Рис.16. Сходження генетичного алгоритму У такій ситуації кросовер практично ніяк не змінює популяції. А що вийшли з цієї області за рахунок мутації особини схильні вимирати, так як частіше мають меншу пристосованість, особливо якщо цей екстремум є глобальним максимумом. Таким чином, сходження популяції зазвичай означає, що знайдене краще або близьке до нього рішення. Види генетичних алгоритмівІснують різні моделі генетичного алгоритму (класичний, простий генетичний алгоритм, гібридний, CHC генетичний алгоритм та ін.) Вони розрізняються по стратегіям відбору та формування нового покоління особин, операторами генетичного алгоритму, кодуванням ген і т.д. CHC -алгоритми CHC (Cross generational elitist selection, Heterogenous recombination, Cataclysmic mutation) був запропонований Есхелманом і характеризується наступними параметрами: 1. Для нового покоління вибираються N кращих різних особин серед батьків і дітей. Дублювання рядків не допускається. 2. Для схрещування вибирається випадкова пара, але не допускається, щоб між батьками було мало Хеммінгово відстань або мало відстань між крайніми розрізняються битами. 3. Для схрещування використовується різновид однорідного кросовера HUX (Half Uniform Crossover): дитині переходить рівно половина бітів кожного з батьків. 4. Розмір популяції невеликий, близько 50 особин. Цим виправдано використання однорідного кросовера. CHC протиставляє агресивний відбір агресивному кросоверу, проте все одно малий розмір популяції швидко викликають стан, коли створюються тільки більш-менш однакові рядки. В такому випадку CHC застосовує cataclysmic mutation: всі рядки, крім самої пристосованої, піддаються сильній мутації (змінюється близько третини бітів). Таким чином, алгоритм перезапускается і далі продовжує роботу, застосовуючи тільки кросовер. Genitor Цей алгоритм був створений Д. Уитли. Genitor-подібні алгоритми відрізняються від класичного ГА наступними трьома властивостями: 1. На кожному кроці тільки одна пара випадкових батьків створює тільки одну дитину. 2. Ця дитина замінює не батьки, а одну з найгірших особин популяції (в первісному Genitor - найгіршу). 3. Відбір особини для заміни проводиться по її ранку (рейтингу), а не по пристосованості. У Genitor пошук гіперплоскостей відбувається краще, а збіжність швидше, ніж у класичного генетичного алгоритму, запропонованого Холландом. гібридні алгоритми Ідея гібридних алгоритмів (hybrid algorithms) полягає в поєднанні генетичного алгоритму з деяким іншим методом пошуку, відповідним в даному завданні. На кожному поколінні кожен отриманий нащадок оптимізується цим методом, після чого виробляються звичайні для генетичного алгоритму дії. Такий вид розвитку називається Ламарковой еволюцією, при якій особина здатна навчатися, а потім отримані навички записувати в свій генотип, щоб потім передати їх нащадкам. І хоча такий метод погіршує здатність алгоритму шукати рішення за допомогою відбору гіперплоскостей, однак на практиці гібридні алгоритми виявляються дуже вдалими. Це пов'язано з тим, що зазвичай велика ймовірність того, що одна з особин потрапить в область глобального максимуму і після оптимізації виявиться рішенням завдання. Паралельні генетичні алгоритми Генетичні алгоритми можна організувати як кілька паралельно виконуються процесів, це збільшить їх продуктивність. Розглянемо перехід від класичного генетичного алгоритму до паралельного. Для цього будемо використовувати турнірний відбір. Заведемо N/2 процесів (тут і далі процес мається на увазі як деяка машина, процесор, який може працювати незалежно). Кожен з них буде вибирати випадково з популяції 4 особи, проводити 2 турніру і схрещувати переможців. Отримані діти будуть записуватися в нове покоління. Таким чином, за один цикл роботи одного процесу буде змінюватися ціле покоління. острівна модель Острівна модель (island model, рис. 17) - це теж модель паралельного генетичного алгоритму. Вона полягає в наступному: нехай у нас є 16 процесів і 1600 особин. Розіб'ємо їх на 16 подпопуляцій по 100 особин. Кожна з них буде розвиватися окремо за допомогою якогось генетичного алгоритму. Таким чином, можна сказати, що ми розселили особини по 16-ти ізольованим островам.
Мал. 17. Острівна модель генетичного алгоритму Зрідка (наприклад, кожні 5 поколінь) процеси (або острова) обмінюватимуться декількома хорошими особинами. Це називається міграція. Вона дозволяє островам обмінюватися генетичним матеріалом. Так як населеність островів зазвичай буває невелика, подпопуляціі будуть схильні до передчасної збіжності. Тому важливо правильно встановити частоту міграції. Надто часта міграція (або міграція занадто великого числа особин) призведе до змішання всіх подпопуляцій, і тоді острівна модель буде несильно відрізнятися від звичайного генетичного алгоритму. Якщо ж міграція буде занадто рідкою, то вона не зможе запобігти передчасного сходження подпопуляцій. Генетичні алгоритми стохастичного, тому при різних його запусках популяція може сходитися до різним рішенням (хоча всі вони в деякій мірі «хороші»). Острівна модель дозволяє запустити алгоритм відразу кілька раз і намагатися поєднувати «досягнення» різних островів для отримання в одній з подпопуляцій найкращого рішення. Ніздрюваті генетичні алгоритми Ніздрюваті генетичні алгоритми (Cellular Genetic Algorithms) - модель паралельних генетичних алгоритмів. Нехай дано 2500 процесів, розташованих на сітці розміром 50 × 50 осередків, замкнутої, як показано на малюнку 18 (ліва сторона замикається з правого, верхня з нижньої, виходить тор). Кожен процес може взаємодіяти тільки з чотирма своїми сусідами (зверху, знизу, зліва, справа). У кожному осередку знаходиться рівно одна особина. Кожен процес обиратиме найкращу особина серед своїх сусідів, схрещувати з нею особина з свого осередку і одного отриманого дитини поміщати в свій осередок замість батька.
Мал. 18. Ніздрюватий генетичний алгоритм У міру роботи такого алгоритму виникають ефекти, схожі на острівну модель. Спочатку все особини мають випадкову пристосованість (на малюнку вона визначається за кольором). Через кілька поколінь утворюються невеликі області схожих особин з близької пристосованістю. У міру роботи алгоритму ці області ростуть і конкурують між собою. Тест по темі «Еволюційний моделювання» 1. Хто вважається «батьком» генетичних алгоритмів? a) Д. Голдберг b) Д. Холланд c) К. Де Йонг d) Немає правильної відповіді 2. Які методи відносяться до напряму «Еволюційний моделювання»? a) Метод групового урахування аргументів b) Нейронні мережі c) Генетичні алгоритми d) Еволюційний програмування e) Евристичне програмування 3. Які поняття відносяться до генетичних алгоритмів? a) особина b) фенотип c) ген d) ДНК e) нейрон f) функція активації 4. Які види відбору в генетичних алгоритмах існують? a) Дискретний відбір b) Рангове відбір c) Поетапний відбір d) Дуельний відбір e) Турнірний відбір f) Рулетка 5. Які бувають оператори генетичного алгоритму? a) кроссинговер b) схрещування c) транслітерація d) транслокация e) мутація f) конверсія 6. Які види генетичного алгоритму мають на увазі паралельну обробку? a) genitor b) CHC c) гібридні алгоритми d) острівна модель e) немає правильної відповіді 7. З якого числа особин можна вибирати пару (другого з батьків) для особини в острівній моделі? a) m, де m - число особин в популяції b) m-1, де m - число особин в популяції c) 4 d) 8 e) t, вибирається випадковим чином, найчастіше t = 2 f) Ні правильної відповіді 8. Який оператор застосований до особи (0001000 -> 0000000)? a) інверсії b) кросовер c) схрещування d) немає правильної відповіді Література по темі «Еволюційний моделювання»: 1) Вороновський Г.К. Махота К.В. Шів С.Н. Сергєєв С.А. Генетичні алгоритми, штучні нейронні мережі і проблеми віртуальної реальності. Х.: ОСНОВА, 1997. - с.112. 2) Ісаєв С.А. Популярно про генетичні алгоритми. http://algolist.manual.ru/ai/ga/ga1.php 3) Каширіна І.Л. Введення в еволюційне моделювання. Навчальний посібник. Воронеж. 2007. с. 40. 4) Стариков А. Лабораторія BaseGroup. Генетичні алгоритми - математичний апарат. http://www.basegroup.ru/genetic/ 5) Фогель Л., Оуенс А., Уолш М. Штучний інтелект і еволюційне моделювання. М .: Світ, 1969. 230 с. 6) ямок Б. Генетичні алгоритми. Санкт-Петербурзький державний університет. 2005. http://rain.ifmo.ru/cat/view.php/theory/unsorted/genetic-2005 §4. Нечіткі множини і нечітка логіка В основі нечіткої логіки лежить теорія нечітких множин, викладена в серії робіт Л. Заде в 1965-1973 роках. Математична теорія нечітких множин (fuzzy sets) і нечітка логіка (fuzzy logic) є узагальненнями класичної теорії множин і класичної формальної логіки. Основною причиною появи нової теорії стало наявність нечітких і наближених міркувань при описі людиною процесів, систем, об'єктів. Л. Заде, формулюючи це головна властивість нечітких множин базувався на працях попередників. На початку 1920-х років польський математик Лукашевич трудився над принципами багатозначною математичної логіки, в якій значеннями предикатів могли бути не тільки «істина» або «брехня». У 1937 р ще один американський вчений Макс Блек вперше застосував багатозначну логіку Лукашевича до списків як безлічам об'єктів і назвав такі безлічі невизначеними. Перш ніж нечіткий підхід до моделювання складних систем отримав визнання у всьому світі, пройшло не одне десятиліття з моменту зародження теорії нечітких множин. Нечітка логіка як наукова дисципліна розвивалася складно і непросто, не уникла вона і звинувачень в лженауковість. Навіть в 1989 році, коли приклади успішного застосування нечіткої логіки в обороні, промисловості і бізнесі обчислювалися десятками, Національне наукове товариство США обговорювало питання про виключення матеріалів по нечітким множинам з інститутських підручників. Перший період розвитку нечітких систем (кінець 60-х-початок 70 рр.) Характеризується розвитком теоретичного апарату нечітких множин. У 1970 р Беллмана спільно з Заде розробив теорію прийняття рішень в нечітких умовах. У другому періоді (70-80-ті роки) з'являються перші практичні результати в області нечіткого управління складними технічними системами (парогенератор з нечітким керуванням). І. Мамдані в 1975 р спроектував перший функціонуючий на основі алгебри Заде контролер, керуючий паровою турбіною. Одночасно стало приділятися увага питанням побудови експертних систем, побудованих на нечіткій логіці, розробці нечітких контролерів. Нечіткі експертні системи для підтримки прийняття рішень знаходять широке застосування в медицині та економіці. Нарешті, в третьому періоді, який триває з кінця 80-х років і триває в даний час, з'являються пакети програм для побудови нечітких експертних систем, а області застосування нечіткої логіки помітно розширюються. Вона застосовується в автомобільній, аерокосмічній і транспортної промисловості, в області виробів побутової техніки, у сфері фінансів, аналізу і прийняття управлінських рішень та багатьох інших. Крім того, чималу роль у розвитку нечіткої логіки зіграло доказ знаменитої теореми FAT (Fuzzy Approximation Theorem) Б. Коско, в якій стверджувалося, що будь-яку математичну систему можна апроксимувати системою на основі нечіткої логіки. Одним з найбільш вражаючих результатів стало створення керуючого мікропроцесора на основі нечіткої логіки, здатного автоматично вирішувати відому «завдання про собаку, наздоганяючої кота». У 1990 році Комітет з контролю експорту США вніс нечітку логіку в список критично важливих оборонних технологій, що не підлягають експорту потенційному супротивникові. У бізнесі і фінансах нечітка логіка отримала визнання після того, як в 1988 році експертна система на основі нечітких правил для прогнозування фінансових індикаторів єдина передбачила біржовий крах. І кількість успішних фаззі-застосувань в даний час обчислюється тисячами. В Японії цей напрямок переживає справжній бум. Тут функціонує спеціально створена організація - Laboratory for International Fuzzy Engineering Research. Програмою цієї організації є створення більш близьких людині обчислювальних пристроїв. Інформаційні системи, що базуються на нечітких множинах і нечіткої логіки, називають нечіткими системами. Переваги нечітких систем: - функціонування в умовах невизначеності; - оперування якісними і кількісними даними; - використання експертних знань в управлінні; - побудова моделей наближених міркувань людини; - стійкість при дії на систему всіляких збурень. Недоліками нечітких систем є: - відсутність стандартної методики конструювання нечітких систем; - неможливість математичного аналізу нечітких систем існуючими методами; - застосування нечіткого підходу в порівнянні з імовірнісним не приводить до підвищення точності обчислень. Теорія нечітких множинГоловна відмінність теорії нечітких множин від класичної теорії чітких множин полягає в тому, що для чітких множин результатом обчислення характеристичної функції можуть бути тільки два значення - 0 або 1, то для нечітких множин це кількість нескінченно, але обмежена діапазоном від нуля до одиниці. нечітке безліч Нехай U - так зване універсальне безліч, з елементів якого утворені всі інші множини, що розглядаються в даному класі задач, наприклад множина всіх цілих чисел, безліч всіх гладких функцій і т.д. Характеристична функція безлічі
В теорії нечітких множин характеристична функція називається функцією приналежності, а її значення Більш строго, нечітким безліччю A називається сукупність пар
де Нехай, наприклад, U = {a, b, c, d, e}, Приклад. Нехай універсум U є безліч дійсних чисел. Нечітке безліч A, що позначає безліч чисел, близьких до 10, можна задати наступною функцією приналежності (рис. 19):
Мал. 19. Функція приналежності Показник ступеня m вибирається залежно від ступеня близькості до 10. Наприклад, для опису безлічі чисел, дуже близьких до 10, можна покласти m = 4, для безлічі чисел, що не дуже далеких від 10, m = 1. Носієм нечіткої множини A називається чітке безліч Ядром нечіткої множини A називається чітке безліч безліччю рівня Функцію приналежності називають нормальною, якщо ядро нечіткої множини містить хоча б один елемент. Операції над нечіткими множинами Для нечітких множин, як і для звичайних, визначені основні операції: об'єднання, перетин і інверсія / доповнення. Для визначення перетину і об'єднання нечітких множин найбільшою популярністю користуються такі три групи операцій:
Доповнення нечіткої множини у всіх трьох випадках визначається однаково:
Приклад. Нехай A - нечітка множина "від 5 до 8" і B - нечітка множина "близько 4", задані своїми функціями приналежності (рис.20):
Тоді, використовуючи максимина операції, ми отримаємо наступні безлічі, зображені на рис. 21.
При максимина і алгебраическом визначенні операцій не будуть виконуватися закони суперечності і виключення третього:
а в разі обмежених операцій не будуть виконуватися властивості ідемпотентності і дистрибутивности:
Можна показати, що при будь-якому побудові операцій об'єднання і перетину в теорії нечітких множин доводиться відкидати або закони суперечності і виключення третього, або закони ідемпотентності і дистрибутивности. нечітка логікаПоняття нечіткої і лінгвістичної змінних використовується при описі об'єктів і явищ за допомогою нечітких множин. Нечітка змінна характеризується трійкою, де a - найменування змінної, X - універсальна множина (область визначення a), Лінгвістичної змінної називається набір, де b - найменування лінгвістичної змінної, Т - безліч її значень (терм-множина), що представляють собою найменування нечітких змінних, областю визначення кожної з яких є безліч X (безліч T називається базовим терм-множиною лінгвістичної змінної), G - синтаксична процедура, що дозволяє оперувати елементами терм-множини T, зокрема, генерувати нові терми (значення), М - семантична процедура, що дозволяє перетворити кожне нове значення лінгво тичної змінної, утворене процедурою G, в нечітку змінну, тобто сформувати відповідне нечітке безліч. Лінгвістичну змінну можна визначити як змінну, значеннями якої є не числа, а слова або пропозиції природного (або формального) мови. Наприклад, лінгвістична змінна "вік" може набувати таких значень: "дуже молодий", "молодий", "середнього віку", "старий", "дуже старий" і ін. Ясно, що змінна "вік" буде звичайною змінною, якщо її значення - точні числа; лінгвістичної вона стає, будучи використаною в нечітких міркуваннях людини. Кожному значенню лінгвістичної змінної відповідає певна нечітка множина зі своєю функцією приналежності. Так, лінгвістичного значенням "молодий" може відповідати програмній клавіші приналежності, зображена на рис.22.
Рис.22. Функція приналежності значення «молодий» лінгвістичної змінної «вік» Приклад: Нехай експерт визначає товщину виробу, що випускається за допомогою понять "мала товщина", "середня товщина" і "велика товщина", при цьому мінімальна товщина дорівнює 10 мм, а максимальна - 80 мм (рис. 23). Формалізація такого опису може бути проведена за допомогою наступної лінгвістичної змінної , де b - товщина вироби; Поряд з розглянутими вище базовими значеннями лінгвістичної змінної "товщина" (Т = { "мала товщина", "середня товщина", "велика товщина"}) можливі значення, що залежать від області визначення Х. В даному випадку значення лінгвістичної змінної "товщина вироби" можуть бути визначені як "близько 20 мм", "близько 50 мм", "близько 70 мм", тобто у вигляді нечітких чисел.
Нечіткими висловлюваннями будемо називати висловлювання такого вигляду: 1. Висловлювання, де b - найменування лінгвістичної змінної, b '- її значення, якому відповідає нечітка множина на універсальній множині Х. 2. Висловлення, де m - модифікатор, якому відповідають слова «дуже», «більш-менш», «багато більше» і ін. Наприклад: <�тиск дуже велике »,« швидкість багато більше середньої> і ін. 3. Складові висловлювання, освічені з висловлювань видів 1. і 2. і союзів "І", "АБО", "ЯКЩО.., ТО ...", "ЯКЩО .., ТО .., ІНАКШЕ". Основним правилом виведення в традиційній логіці є правило modus ponens, згідно з яким ми судимо про істинність висловлювання B по істинності висловлювань A і Наприклад, якщо A - висловлювання "Іван в лікарні", B - висловлювання "Іван хворий", то якщо істинні висловлювання "Іван в лікарні" і "Якщо Іван в лікарні, то він хворий", то істинно і висловлювання "Іван хворий". У багатьох звичних міркуваннях, однак, правило modus ponens використовується не в точної, а в наближеною формі. Так, звичайно ми знаємо, що A істинно і що Нечітка імплікація виражається в наступному вигляді:
Основою для проведення операції нечіткого логічного висновку є база правил, що містить нечіткі висловлювання у формі "Якщо щось" і функції приналежності для відповідних лінгвістичних термів. При цьому повинні дотримуватися наступні умови: - існує хоча б одне правило для кожного лінгвістичного терма вихідної змінної; - для будь-якого терма вхідної змінної є хоча б одне правило, в якому цей терм використовується в якості передумови (ліва частина правила). В іншому випадку має місце неповна база нечітких правил. Для реалізації логічного висновку необхідно виконати наступне: 1. Зіставити факти з кожним з правил і визначити ступінь відповідності, призначивши поточну силою правил. 2. Для кожного правила, сила якого більше заданого порогу обчислити вірогідність лівій частині. 3. Для кожного правила за допомогою оператора імплікації обчислити вірогідність правій частині. 4. Для багатьох результатів, отриманих за різними правилами, вибрати одне (усереднене) Приклад. Нехай є деяка система, наприклад, реактор, описувана трьома параметрами: температура, тиск і витрата робочої речовини. Всі показники вимірні, і безліч можливих значень відомо. Також з досвіду роботи з системою відомі деякі правила, що зв'язують значення цих параметрів. Припустимо, що зламався датчик, що вимірює значення одного з параметрів системи, але знати його показання необхідно хоча б приблизно. Тоді постає завдання про відшукання цього невідомого значення (нехай це буде тиск) при відомих показниках двох інших параметрів (температури і витрати) і зв'язку цих величин у вигляді наступних правил:
Температура, тиск і Витрата - лінгвістичні змінні. Температура. Універсум (безліч можливих значень) - відрізок [0, 150]. Початкове безліч термів {Висока, Середня, Низька}. Функції приналежності термів мають такий вигляд (рис. 25):
Тиск. Універсум - відрізок [0, 100]. Початкове безліч термів {Висока, Середнє, Низьке}. Функції приналежності термів мають такий вигляд (рис. 26):
Витрата. Універсум - відрізок [0, 8]. Початкове безліч термів {Великий, Середній, Малий}. Функції приналежності термів мають такий вигляд (рис. 27):
Нехай відомі значення Температура - 85 і Витрата - 3,5. Зробимо розрахунок значення тиску. Етап фазифікації (перехід від заданих чітких значень до ступенями впевненості). За заданим значенням вхідних параметрів знайдемо ступеня впевненості найпростіших тверджень:
Потім обчислимо ступеня впевненості посилок правил:
Кожне з правил вдає із себе нечітку імплікації. Ступінь впевненості посилки ми вирахували, а ступінь впевненості укладення задається функцією приналежності відповідного терма. Тому, використовуючи один із способів побудови нечіткої імплікації, ми отримаємо нову нечітку змінну, відповідну ступеня впевненості в значенні вихідних даних при застосуванні до заданим вхідним відповідного правила. Використовуючи визначення нечіткої імплікації як мінімуму лівої і правої частин (визначення Мамдані), маємо (рис. 28):
Етап акумуляції (об'єднання результатів застосування всіх правил). Один з основних способів акумуляції - побудова максимуму отриманих функцій приналежності (об'єднання функцій приналежності, отриманих на етапі фазифікації). Отриману функцію приналежності вже можна вважати результатом. Це новий терм вихідної змінної Тиск. Його функція приналежності говорить про ступінь впевненості в значенні тиску при заданих значеннях вхідних параметрів і використанні правил, що визначають співвідношення вхідних і вихідних змінних. Але зазвичай все-таки необхідно якесь конкретне числове значення.
Рис.29. Результат етапу акумуляції. Етап дефаззифікації (отримання конкретного значення з універсал по заданій на ньому функції приналежності). Існує безліч методів дефаззифікації, але в цьому випадку досить методу першого максимуму. Застосовуючи його до отриманої функції приналежності, отримуємо, що значення тиску - 50. Таким чином, якщо ми знаємо, що температура дорівнює 85, а витрата робочої речовини - 3,5, то можемо зробити висновок, що тиск в реакторі дорівнює приблизно 50. Тест по темі «Нечіткі безлічі і нечітка логіка» 1. Хто заклав основи теорії нечітких множин? a) І. Мамдані b) М. Блек c) Л. Заде d) Б. Коско e) Немає правильної відповіді 2. Функція приналежності може приймати значення ..? a) [0, ∞] b) [-∞, + ∞] c) [0, 1] d) Немає правильної відповіді 3. Безліч точок, для яких функція приналежності дорівнює 1, називається? a) носієм b) ядром c) d) Немає правильної відповіді 4. Об'єднання нечітких множин А і В визначає яка з формул? a) b) c) d) e) Немає правильної відповіді 5. У разі обмежених операцій не будуть виконуватися ..? a) b) c) d) Немає правильної відповіді
a) b) c) d) e) Немає правильної відповіді 7. Нехай а) m С (u) = max {m В (u), m А (u)) = 0,5 b) m С (u) = min {m В (u), m А (u)) = 0 c) m С (u) = 1 min {m В (u), m А (u)) = 1 d) Немає правильної відповіді 8.нехай a) m С (u) = max {m В (u), m А (u)) = 0,5 b) m С (u) = min {m В (u), m А (u)) = 0 c) m С (u) = 1 max {m В (u), m А (u)) = 0,5 d) m С (u) = 1 min {m В (u), m А (u)) = 1 e) Немає правильної відповіді Література по темі «Нечіткі безлічі і нечітка логіка» 1. Круглов В.В., Дли М.І., Голунь Р.Ю. Нечітка логіка і штучні нейронні мережі. М .: ФИЗМАТЛИТ, 2001. - с. 224. 2. Паклин Н. Нечітка логіка - математичні основи. http://www.basegroup.ru/library/analysis/fuzzylogic/math/ 3. Півкін В. Я., Бакулін Є. П., Кореньков Д. І. Нечіткі безлічі в системах управління / під редакцією д.т.н. н., проф. Ю.Н. Золотухіна, НГУ (електронний посібник). http://www.vevivi.ru/best/Nechetkie-mnozhestva-v-sistemakh-upravleniya-ref41397.html 4. Прикладні нечіткі системи: пров. з япон. / К.Асаі, Д. Ватада, С. Іваї і ін .; під редакцією Т. Тера, К. Асаи, М. Сугено. - М.: Мир, 1993. - с. 368. 5. Штовба С.Д. Введення в теорію нечітких множин і нечітку логіку. http://matlab.exponenta.ru/fuzzylogic/book1/index.php Частина 3. Інтелектуальні інформаційні системи §1. експертні системи На початкових етапах розвитку штучний інтелект піддавався жорсткій критиці і одним з доводів був той, що практичної користі від нього немає, він займається іграшками. Експертні системи одними з перших довели практичну користь цього наукового напрямку, приносячи на початку 80-х років ХХ століття комерційний прибуток своїм творцям. Термін "системи, засновані на знаннях" (knowledge-based systems) з'явився в 1976 році одночасно з першими системами, що акумулюють досвід і знання експертів. Експертні системи - це прикладні системи штучного інтелекту, в яких база знань являє собою формалізовані емпіричні знання висококваліфікованих фахівців (експертів) в будь-якої вузької предметної області, вони акумулюють ці знання і тиражують їх для консультації менш кваліфікованих фахівців. У 1965 році Е. Фейгенбаум (колишній студент Герберта Саймона), Б. Б'юкенен (філософ за освітою) і Д. Ледербергом (лауреат Нобелівської премії в області генетики) почали роботи над першою експертною системою DENDRAL. У 1969 році була створена математична експертна система MACSYMA В. Мартіном і Д. Мозесом. Перша експертна система для медичної діагностики була створена в 1973 році Е. Шортліффом і називалася MYCIN, вона спричинила за собою розробку першого командного інтерпретатора EMYCIN (В. Мілле, Шортліфф і Б'юкенен). У 1976 році Дуда і Харт почали роботу над експертною системою PROSPECTOR, призначеної для розвідки корисних копалин, в 1984 році система точно передбачила існування родовища молібдену, оціненого в багатомільйонну суму. Ці експертні системи, розроблені в 60-70-х роках стали класичними. За походженням, предметних областях і по наступності застосовуваних ідей, методів і інструментальних програмних засобів їх можна розділити на кілька сімейств. 1. META - DENDRAL Система DENDRAL дозволяє визначити найбільш ймовірну структуру хімічної сполуки за експериментальними даними (мас-спектрограф, даними ядерному магнітного резонансу та ін.). Meta-DENDRAL автоматизує процес придбання знань для DENDRAL. Вона генерує правила побудови фрагментів хімічних структур. 2. MYCIN - EMYCIN - TEIREIAS - PUFF - NEOMYCIN. Це сімейство медичних ЕС і сервісних програмних засобів для їх побудови. 3. PROSPECTOR - KAS. PROSPECTOR - призначена для пошуку (передбачення) родовищ на основі геологічних аналізів. KAS - система придбання знань для PROSPECTOR. 4. CASNET - EXPERT. Система CASNET - медична ЕС для діагностики видачі рекомендацій по лікуванню очних захворювань. На її основі розроблена мова інженерії знань EXPERT, за допомогою якої створено ряд інших медичних діагностичних систем. 5. HEARSAY - HEARSAY -2- HEARSAY -3- AGE. Перші дві системи цього ряду є розвитком інтелектуальної системи розпізнавання злитої людської мови, слова якої беруться із заданого словника. Ці системи відрізняються оригінальною структурою, заснованої на використанні дошки оголошень-глобальної бази даних, що містить поточні результати роботи системи. Надалі на основі цих систем були створені інструментальні системи HEARSAY-3 і AGE (Attempt to Generalize- спроба спілкування) для побудови експертних систем. 6. Системи AM (Artifical Mathematician - штучний математик) і EURISCO були розроблені в Стенфордському університеті доктором Дугласом Ленатом для дослідницьких і навчальних цілей. У систему AM спочатку було закладено близько 100 правил виводу і більше 200 евристичних алгоритмів навчання, що дозволяють будувати довільні математичні теорії та уявлення. EURISCO - це розвиток системи AM, з її допомогою у військово-стратегічній грі, що проводиться ВМФ США, була розроблена стратегія, яка містить ряд оригінальних тактичних ходів. Крім розробки самих експертних систем дослідники зайнялися створенням інструментальне засіб для експертних систем: в 1983 році компанія IntelliCorp створила KEE, а в 1985 році агентство NASA випустило першу версію CLIPS. Експертні системи швидко завоювали позиції на інформаційному рикну і набули широкого расмпостраненіе. Уже в 1987 році опитування користувачів, проведене журналом "Intelligent Technologies" (США), показав, що приблизно: - 25% користувачів використовують ЕС; - 25% збираються придбати ЕС в найближчі 2-3 роки; - 50% вважають за краще провести дослідження про ефективність їх використання. У Росії в дослідження і розробку ЕС великий внесок внесли роботи Д. А. Поспєлова (засновника Російської асоціації штучного інтелекту і його першого президента), Е. В. Попова, В. Ф. Хорошевского, В. Л. Стефанюка, Г. С. Осипова, В. К. Фінна, В. Л. Вагіна, В. І. Городецького і багатьох інших. Експертні системи 60-90-их років є першим поколінням експертних систем, для них характерно: 1) знаннями системи є тільки знання експерта, накопичення знань не передбачається; 2) методи представлення знань дозволяють описувати лише статичні предметні області; 3) моделі представлення знань орієнтовані на прості предметні області. Розвиваючись, експертні системи вийшли за ці рамки. Принципи представлення знань в експертних системах другого покоління змінилися: 1) використовуються не поверхневі знання, а більш глибинні; 2) для представлення знань залучаються кошти і методи інших напрямків штучного інтелекту, наприклад, нейронних мереж; 3) системи мають динамічної бази знань. Поява інтернету не могло не вплинути на розвиток експертних систем. Можливість отримувати знання через мережу і отримувати знання з мережі не могла не бути використана розробниками. Тому зараз розвиваються розподілені і web-орієнтовані експертні системи. Зараз кількість експертних систем обчислюється тисячами і десятками тисяч. У розвинених зарубіжних країнах сотні фірм займаються їх розробкою та впровадженням в різні сфери життя. Як сучасних ЕС можна назвати швидкодіючу систему OMEGAMON (фірма Candle, з 2004 р IBM) для відстеження стану корпоративної інформаційної мережі і G2 (фірма Gensym) - комерційну експертну систему для роботи з динамічними об'єктами. Експертні системи використовують в тих випадках, коли недостатньо експертів, в небезпечних (шкідливих) для них умовах, в процесі навчання. Експертні системи вирішують завдання, для вирішення яких відсутні чіткі алгоритми рішення. Модель експертних системЕкспертні системи працюють в діалоговому режимі (відповідають на поставлені користувачем питання), при цьому, вони повинні вміти пояснювати, звідки отримано те чи інше рішення, будь-яка експертна система містить як мінімум п'ять компонентів або підсистем (рис. 30).
Мал. 30. Базова структура експертної системи Користувач експертної системи - фахівець предметної області, для якого призначена система. Зазвичай його кваліфікація недостатньо висока і тому він потребує допомоги та інформаційної підтримки своєї діяльності. Інженер по знаннях - фахівець в області штучного інтелекту, який працює з експертами і формує базу знань. Синоніми: когнитологией, інженер-інтерпретатор, аналітик. Інтерфейс користувача - комплекс програм, що реалізують діалог користувача з ЕС як на стадії введення інформації, так і при отриманні результатів. База знань - ядро експертної системи, сукупність знань предметної області, записана на машинний носій в формі, зрозумілою експерту і користувачу (зазвичай на деякій мові, наближеному до природного). Вирішувач - програма, що моделює хід міркувань експерта на підставі знань, наявних в базі знань. Синоніми: дедуктивна машина, машина виведення, блок логічного висновку. Підсистема пояснень - програма, що дозволяє користувачеві отримати відповіді на питання: "Як була отримана та чи інша рекомендація?" і "Чому система прийняла таке рішення?" Відповідь на питання "як" - це трасування всього процесу отримання рішення із зазначенням використаних фрагментів бази знань, т. Е. Всіх кроків ланцюга умовиводів. Відповідь на питання "чому" - посилання на умовивід, безпосередньо передувала отриманому рішенню, т. Е. Відхід на один крок назад. Розвинені підсистеми пояснень підтримують і інші типи питань. Інтелектуальний редактор бази знань - програма, що представляє інженеру по знаннях можливість створювати базу знань в діалоговому режимі. Включає в себе систему вкладених меню, шаблонів мови представлення знань, підказок і інших сервісних засобів, що полегшують роботу з базою. Описана структура є базовою і може розширюватися (рис. 31).
Мал. 31. Структура експертної системи Окреслені штриховий лінією підсистеми моделювання зовнішнього світу, інтерфейс із зовнішнім світом, система датчиків - необхідні для експертних систем реального часу для отримання даних та їх інтерпретації. Експертні системи можуть накопичувати досвід у вигляді прецедентів (вже дозволених ситуацій), які зберігаються в базі знань і використовуються в подальшому. Блок алгоритмічних методів рішення включає в себе всі обчислювальні операції і алгоритми, що реалізуються методами традиційного програмування, інтегровані в експертну систему.Об'єднання в рамках експертної системи методів традиційного програмування і штучного інтелекту дозволяє значно підвищити ефективність і якість прийнятих рішень. Специфіка предметної області, для якої будується система, відображається описується не тільки в базі знань, а й в підсистемі «Контекст предметної області», яка дозволяє більш наочно уявити вхідну і вихідну інформацію в прийнятому для конкретної предметної області вигляді. Сучасні інформаційні системи часто використовують архітектуру клієнт-сервер, що дозволяє будувати розподілені і мережеві додатки. При клієнт-серверній архітектурі експертної системи на стороні клієнта знаходяться інтерфейси користувача, експерта, зовнішнього середовища і система датчиків. Решта блоки розташовуються на серверній стороні. Класифікація експертних систем і оболонок експертних системІснуюче безліч експертних ділиться на кілька класів (рис.32) за різними критеріями. За призначенням виділяють системи загального призначення, які претендують на універсальність у вирішенні завдань (CASNET), спеціалізовані, вирішальні конкретну задачу (1-st Clas, Еліс) або орієнтовані на певну предметну область (MYCIN, MACSYMA, МОДІС, ДІАГЕН, INTERNIST-I) . За критерієм взаємодії із зовнішнім середовищем розрізняють статичні системи, в яких є тільки інтерфейс користувача, а механізму взаємодії з зовнішнім світом, наприклад, через датчики, відсутня. Динамічні експертні системи за допомогою вбудованих інтерфейсів отримують інформацію з зовнішніх датчиків або інших пристроїв. Квазідінаміческіе експертні системи отримують інформацію про зміну ситуації в зовнішньому середовищі через заданий проміжок часу (більше декількох секунд). Експертні системи розробляються для різних ЕОМ і розрізняються по апаратно-програмній платформі. Вони розробляються і експлуатуються на персональних (PROSPECTOR), на символьних (Picon), на міні (СПЕІС) і на суперкомп'ютерах (ЕКСПЕРТИЗА). За ступенем інтеграції ділять експертні системи на автономні програмні комплекси (ДАМП), які працюють самостійно, або експертна система може бути частиною більш загальної системи (інтегровані системи) або ж бути ланкою в ланцюжку програм,
Рис 32. Класифікація експертних систем обробляють інформацію з спільною метою, наприклад управління підприємством. Залежно від розміру бази знань виділяють прості експертні системи - до 1000 простих правил (GUIDON, Гребля), - середні - від 1000 до 10000 структурованих правил (XCON, GOSSEYN, ДІАГЕН) - і складні - більше 10000 структурованих правил. Експертні системи розрізняються по стадії існування, тобто за ступенем завершеності системи. Перша стадія існування експертної системи - це дослідницький зразок - розробляється 3-6 місяці з мінімальною базою знань (SYSTEM-D, SYN), друга - демонстраційний зразок - розробляється 6-12 місяці (THYROID MODEL), третя - промисловий зразок - розробляється 1 1,5 року з повною базою знань (PUFF, FOSSIL) і остання - комерційний зразок - розробляється 1,5-3 роки з повною базою знань (KNEECAP, MACSYMA). Засоби розробки експертних системІснуючі засоби розробки експертних систем можна розділити на 3 класу (рис. 33). Традиційні мови програмування (C ++, Java, Delphi) дозволяють побудувати експертні системи «з нуля» для конкретного завдання або предметної області, забезпечивши хороші показники якості і необхідну функціональність системи, але на розробку потрібні значні часові та фінансові ресурси. Так створюють експертні системи будь-якій стадії існування, особливо, комерційні системи, продаж яких відшкодує витрати. Мови штучного інтелекту (LISP, PROLOG, Рефал) були розроблені спеціально для представлення знань, побудова з їх допомогою експертних систем дозволяє більш легко оперувати експертними знаннями, але обмежують спосіб їх подання структурою мови. За допомогою мов штучного інтелекту створюються дослідницькі та демонстраційні зразки. Наступний клас засобів побудови експертних систем - спеціальний програмний інструментарій - орієнтований тільки на створення інтелектуальних інформаційних систем і ділиться на два підкласу: оболонки і середовища розробки інтелектуальних систем. Середовища розробки є програмними комплексами, що дозволяють будувати системи з окремих готових блоків, на їх основі створюються демонстраційні і промислові зразки експертних систем. Оболонка експертних систем - інструментальний засіб для проектування і створення експертних систем. До складу оболонки входять засоби проектування бази знань з різними формами представлення знань і вибору режиму роботи решателя завдань. Для конкретної предметної області інженер по знаннях визначає потрібне подання знань і стратегії вирішення завдань, а потім, вводячи їх в оболонку, створює конкретну експертну систему.
Рис.33. Класифікація інструментальних засобів розробки ЕС Застосування оболонки дозволяє досить швидко і з мінімальними витратами створити дослідницьку, демонстраційну або промислову експертну систему. Оболонки можна класифікувати наступним чином (рис.34). За ступеня обробки виділяють експериментальну (GPSI), дослідницьку (Expert) і комерційну (EXSYS) оболонки.
Рис.34. Класифікація оболонок експертних систем Знання в базі можуть бути представлені одним способом (EMYCIN, CLIPS) - семантичної мережею, продукціям, фреймами і т.д.) або ж декількома (MINEVRA, EsWin), для створення більш повної, гнучкою і наочної моделі предметної області. Використовувані в оболонці методи можуть бути традиційними (CubiCalc, NEXPERT, Алеф) - алгоритми, дерева виводу і т.д. - і гібридними (FuzzyCLIPS, MultiNeuron) - спільно з традиційними використовуються нейронні мережі, нечітка логіка і т.д. Існують статичні оболонки, призначені для вирішення статичних задач (1-st Clas, Еліс). Вони характеризуються використанням поверхневої технології, загальних правил і пошуку рішення від мети до даних, застосовуються для вирішення завдань аналізу. Статичні оболонки, призначені для вирішення завдань аналізу та синтезу з поділом часу (KAPPA, Clips), використовують глибинний і структурний підходи, здійснюють пошук рішень - від мети до даних і від даних до мети. Оболонки для проектування динамічних систем (Framework, NExpert) застосовують поверхневий підхід, приймають рішення на основі правил загального вигляду. Оболонки для розробки динамічних систем (G2, Rethink, RkWorks) мають підсистему моделювання, планувальника рішень, використовують змішану технологію, правила загального і приватного виду, рішення задачі аналізу та синтезу в реальному часі. EMYCIN - перша оболонка, заснована на MYCIN. Принципи, розроблені для PROSPECTOR, були використані при створенні таких систем, як KAS, SAGE, SAVOIR. Зміна принципів побудови веде до розвитку інструментарію. Тому оболонки пройшли той же еволюційний шлях, що і ЕС. Сучасні оболонки пропонують наступні можливості (в кожній конкретній оболонці представлені частково): - гібридне представлення знань (EsWin); - вибір з кількох стратегій виведення (G2, CLIPS); - підключення бібліотек та інших систем (ACTIVATION FRAMEWORK); - архітектура на основі «дошки оголошень» (HEARSAY-III); - архітектура «клієнт-сервер» (JESS); - інтеграція в інтернет / інтранет (Egg2Lite, Exsys Corvid); - графічний інтерфейс (WindExS, WxCLIPS); - підсистема моделювання (G2); - модульне побудова системи (ReThink, G2); - візуалізація структури БЗ (WEST) і т.д. Тест по темі «Експертні системи» 1. Як називалася перша експертна система? a) MACSYMA b) EMYCIN c) PROSPECTOR d) немає правильної відповіді 2. Яке завдання вирішувала експертна система PROSPECTOR? a) визначення найбільш вірогідною структури хімічної сполуки b) пошуку родовищ на основі геологічних аналізів c) діагностика очних захворювань d) розпізнавання злитої людської мови e) немає правильної відповіді 3. Які підсистеми є для експертної системи обов'язковими? a) база знань b) інтерфейс системи із зовнішнім світом c) алгоритмічні методи рішень d) інтерфейс когнітолога e) контенкст предметної області 4. Яка експертна система має базу знань розміром від 1000 до 10000 структурованих правил? a) проста b) середня c) складна 5. Яка експертна система розробляється 1-1,5 год? a) дослідний зразок b) демонстраційна c) комерційна d) немає правильної відповіді 6. Для вирішення яких завдань призначені статичні оболонки експертних систем? a) управління і діагностики в режимі реального часу b) для вирішення статичних задач c) для вирішення завдань аналізу та синтезу з поділом часу d) для розробки динамічних систем e) немає правильної відповіді 7. Гібридна експертна система має на увазі ..? a) використання декількох засобів розробки b) використання різних підходів до програмування c) використання декількох методів представлення знань d) немає правильної відповіді 8. Хто створює базу знань експертної системи? a) програміст b) користувач c) когнитологией d) експерт Література по темі «Експертні системи»: 4. Гаврилова Т.А., Хорошевський В.Ф. Бази знань інтелектуальних систем. СПб .: Пітер, 2001. с. 384. 5. Джарратано Д., Райлт Г. Експертні системи: принципи розробки та програмування, 4-е видання. / Пер. з англ. - М .: ТОВ «І.Д. Вільямс », 2007., - 1152 с. 6. Кобринський Б.А. Ретроспективний аналіз медичних експертних систем // Новини штучного інтелекту, 2005 №2 - с.6-18. 7. Попов Е. В. Експертні системи реального часу // Відкриті системи № 2 (10) 1995. http://www.masters.donntu.edu.ua/2007/kita/kostanda/library/Open_Systems_Magazine.htm 09.05.08 м 8. Рот М. Інтелектуальний автомат: комп'ютер в якості експерта. - М .: Вища школа, 1991. - 80 с. 9. Частиков А.П., Гаврилова Т.А., Бєлов Д.Л. Розробка експертних систем. Середа CLIPS. - СПб .: БХВ-Петербург, 2003. - 608 с. 10. Елті Дж., Кумбс М. Експертні системи: концепції та приклади / Пер. з англ. і предисл. Б.І. Шитикова. - М .: Фінанси і статистика, 1987. - 191 с. §2. Системи підтримки прийняття рішень Системи підтримки прийняття рішень - це програмні засоби та інформаційно-аналітичні технології, призначені спеціально для надання допомоги у вирішенні завдань пошуку, аналізу і вибору кращих з можливих варіантів. При цьому особа, яка приймає рішення, має забезпечуватися не тільки інформаційної, але в першу чергу технологічної підтримкою процедури, аж до вибору кращого рішення. Поняття про підтримку в прийнятті рішень сформулювали П.Кін і Ч. Стейбел. Ранні визначення систем підтримки прийняття рішень (на початку 70-х років минулого століття) відображали такі три властивості систем: - можливість оперувати з неструктурованими або слабоструктурованих завданнями, на відміну від завдань, з якими має справу дослідження операцій; - інтерактивні автоматизовані (тобто реалізовані на базі комп'ютера) системи; - поділ даних і моделей. У сучасному уявленні ідеальна система підтримки прийняття рішень: - оперує зі слабоструктурованих рішеннями; - призначена для особи, яка приймає рішення, різного рівня; - може бути адаптована для групового та індивідуального використання; - підтримує як взаємозалежні, так і послідовні рішення; - підтримує 3 фази процесу рішення: інтелектуальну частину, проектування і вибір; - підтримує різноманітні стилі та методи вирішення, що може бути корисно при вирішенні задачі групою осіб, що приймають рішення; - є гнучкою і адаптується до змін як організації, так і її оточення; - проста у використанні і модифікації; - покращує ефективність процесу прийняття рішень; - дозволяє людині управляти процесом прийняття рішень за допомогою комп'ютера, а не навпаки; - підтримує еволюційне використання і легко адаптується до мінливих вимог; - може бути легко побудована, якщо може бути сформульована логіка конструкції системи підтримки прийняття рішень; - підтримує моделювання; - дозволяє використовувати знання. До середини 60-х років ХХ століття створення великих інформаційних систем було надзвичайно дорогим, тому перші інформаційні системи менеджменту (Management Information Systems) були створені в ці роки лише в досить великих компаніях. Вони призначалися для підготовки періодичних структурованих звітів для менеджерів. Але інформаційні системи здатні набольшее. В кінці 60-х років з'являється новий тип інформаційних систем - модель-орієнтовані системи підтримки прийняття рішень (Decision Support Systems) або системи управлінських рішень (Management Decision Systems). 70-ті роки ХХ століття стали характеризуються періодом виникнення ранніх систем підтримки прийняття рішень і теоретичних досліджень. До 1975 р Дж. Д. Літтл розробив систему Brandaid (Підтримка бренду), яка призначалася для підтримки прийняття рішень у виробництві, просуванні, ціноутворенні і рекламі. Також Літтл в своїй більш ранній статті сформулював критерії щодо формування моделей і систем для підтримки прийняття рішень для менеджменту: надійність, легкість контролю, простота і повнота набору необхідних деталей. На початку 80-х роком дослідники з академічних інститутів створили нову категорію програмного забезпечення для підтримки групового прийняття рішень. Найранішими варіантами таких систем були «Mindsight» компанії «Execucom Systems», «GroupSystems», створені в університеті Арізони Університеті, і система «SAMM», створена дослідниками Університету Міннесоти. У 1984 г.в Університеті Арізони була завершена розробка системи «PLEXSYS» і сформована служба комп'ютеризованої підтримки групових рішень. Нові технології стали використовувати спільно з системами підтримки прийняття рішень. Починаючи приблизно з 1990-го року Б. Інмона і Р. Кімбел стали активно просувати системи підтримки прийняття рішень, побудовані за допомогою технологій реляційних баз даних. Стали активно розроблятися системи підтримки прийняття рішень, заснованим на архітектурі клієнт-сервер, до цього в основному використовувалися великі комп'ютери (mainframe), системи підтримки прийняття рішень стали інтегруватися довготривалі сховища. Системи підтримки прийняття рішень, що використовують можливості інтернет стали реальністю близько 1995 р Структура систем підтримки прийняття рішеньСтруктура системи підтримки прийняття рішень залежить від розв'язуваної задачі, предметної області, апаратно-програмної платформи і конкретної реалізації. У найзагальнішому вигляді систему підтримки прийняття рішення можна представити у вигляді двох підсистем системи підтримки генерації рішень і системи підтримки вибору рішень (рис. 35).
Мал. 35. Узагальнена структура системи підтримки прийняття рішень Системи підтримки генерації рішень можна розділити на евристичні та оптимізаційні. Евристичні технології стимулюють і дисциплінують мислення (наприклад, структурний і морфологічний аналіз), допомагають знаходити варіанти рішень на базі відомих правил, принципів і аналогів. Однак, при формуванні варіантів рішень унікальних завдань (наприклад, при стратегічному плануванні) їх застосовність часто обмежують допоміжними функціями. Оптимізаційні системи підтримки прийняття рішень засновані на методах оптимального структурного синтезу і параметричної оптимізації. Системи підтримки вибору рішень призначені для вибору ефективних варіантів вирішення, згенерованих будь-яким з перерахованих вище методів, або надійшли ззовні (наприклад, заявок на фінансування інвестиційних проектів). Ці системи базуються на методах багатокритеріального аналізу та експертних оцінок. Інший варіант узагальненої архітектури системи підтримки прийняття рішень складається з п'яти частин (рис. 36): джерела даних (часто використовується база даних), система управліннями даними (якщо джерел декілька це підсистема об'єднує, перевіряє і синхронізує їх), моделі управління (включають в себе моделі розв'язуваної задачі і зовнішнього світу), машина виведення (дозволяє за допомогою наявних даних і моделей отримати і обгрунтувати рішення) і інтерфейс користувача.
Мал. 36. Компоненти системи підтримки прийняття рішень Систему підтримки прийняття рішень можна представити у вигляді процесів (рис. 37).
Мал. 37. Процеси системи підтримки прийняття рішень Система проводить збір запитуваних у користувача або зовнішніх датчиків даних і вкладених в неї при створенні даних і знань. Після цього визначає стан, в якому знаходиться система і вирішити завдання, критерії та цілі (може запитувати й уточнювати у користувача). На основі отриманих даних, які містяться в пам'яті, і наявної моделі системи або завдання з урахуванням сформованих критеріїв і цілей генерується безліч рішень, які перевіряються на моделі, і вибирається краще. Після реалізації рішення проводиться оцінка результатів, якщо вона незадовільна, то процес генерації і вибору повторюються з урахуванням нових даних. З інформаційно-аналітичної точки зору завданням системи підтримки прийняття рішень є агрегування (стискання) многокритериальной інформації про аналізовані об'єктах до обсягу та форми подання, які сприймаються особою, яка приймає рішення. З програмно-технологічної точки зору варіанти рішень є для системи прийняття рішень просто аналізованими об'єктами, які характеризуються наборами кількісних і якісних характеристик (показників). Найчастіше системи прийняття рішень використовують при стратегічному плануванні і виборі організації складних систем. Незважаючи на унікальність кожної з таких завдань, при їх вирішенні використовується типова технологія обробки інформації. Тому в світі вже досить широко використовуються універсальні системи підтримки прийняття рішень, призначені для порівняння і вибору варіантів рішень щодо всіх питань. Завдання користувача таких систем полягає в налагодженні універсальної програмної оболонки на потрібну предметну область шляхом введення (імпорту) інформації про аналізовані об'єктах, а також ієрархії вимог і переваг. Для універсальних систем прийняття рішень аналізуються об'єктами можуть бути будь-які об'єкти, для яких потрібно дати оцінку їх відповідності вимогам, що пред'являються за багатьма критеріями, прийняти рішення альтернативного вибору, наприклад, "вибрати найкраще з ..." або "схвалити-відкинути, прийняти рішення про розподіл ресурсів серед групи об'єктів, виходячи з їхньої поточної пріоритетності. Залежно від розв'язуваної задачі і системах підтримки прийняття рішень можуть використовуватися різні методи прийняття рішень, залучатися моделі і методи, розроблені в рамках предметної області. Прикладами методів прийняття рішення є: - декомпозиція головної мети до того рівня деталізації, коли для нижнього рівня ієрархії цілей можна сформулювати критерії, що дозволяють адекватно описати ступінь досягнення цілей при прийнятті тієї чи іншої альтернативи; - метод аналітичних ієрархічних процесів (особа, яка приймає рішення, здійснює спочатку попарне порівняння значущості обраних критеріїв, потім цей же метод використовується для попарного порівняння альтернатив щодо кожного обраного критерію; на основі цього система підтримки прийняття рішень розраховує коефіцієнти значущості критеріїв, коефіцієнти значущості альтернатив щодо кожного критерію, що дозволяє розрахувати для кожної альтернативи значення лінійної функції корисності); - метод аналітичних мережевих процесів, який дозволяє врахувати взаємозв'язки між критеріями; - багатоцільове оцінювання альтернатив (кожна альтернатива оцінюється єдиним показником ефективності - ступенем впливу його виконання на досягнення головної мети). Системи підтримки прийняття рішень починають все ширше застосовуватися державними організаціями та великими корпораціями (US Navy, NASA, IBM, General Motors, Xerox, 3M, Rockwell International, Reiter Consulting Group International і ін.) Приклади завдань, що вирішуються із залученням таких систем: · Обґрунтування напрямків розвитку систем вищої освіти США на період 1985-2000 роки; · Вибір методів завоювання ринку побутової техніки; · Оцінка привабливості в найближчі 10 років регіонів США для працевлаштування людей, які закінчили коледж; розподіл коштів між заходами, спрямованими на зменшення бандитизму; · Оцінка перспективності видів альтернативного пального для автомобілів; розподіл коштів між проектами соціальної програми гуманітарної спрямованості; · Відбір науково-технічних проектів в рамках конкурсу; · Вибір перспективних напрямків інформатизації країни та ін. Останнім часом системи підтримки прийняття рішень починають застосовуватися і в інтересах малого і середнього бізнесу (наприклад, вибір варіанта розміщення торгових точок, вибір кандидатури на заміщення вакантної посади, вибір варіанту інформатизації і т.д.) Класифікація систем підтримки прийняття рішеньЗагальноприйнятою вичерпної класифікації систем підтримки прийняття рішень не існує, але системи підтримки прийняття рішень можна розділити по декількох рівнях. На рівні користувача системи підтримки прийняття рішень можна розділити на: - пасивні; - активні; - кооперативні. Пасивною системою підтримки прийняття рішень називається система, яка допомагає процесу прийняття рішення, але не може винести пропозицію, яке рішення прийняти. Активна система може зробити пропозицію, яке рішення слід вибрати. Кооперативна система дозволяє особі, що приймає рішення, змінювати, поповнювати або покращувати рішення, пропоновані системою, посилаючи потім ці зміни в систему для перевірки. Система змінює, поповнює або покращує ці рішення і посилає їх знову користувачеві. Процес триває до отримання погодженого вирішення. На концептуальному рівні виділяють системи підтримки прийняття рішень, - керовані повідомленнями; - керовані даними; - керовані документами; - керовані знаннями; - керовані моделями. Системи, керовані моделями, базуються на математичних моделях (статистичних, фінансових, оптимізаційних, імітаційних). Для їх побудови можна використовувати OLAP-системи, що дозволяють здійснювати складний аналіз даних, і тоді таку систему підтримки прийняття рішення можна віднести до гібридних систем, які забезпечують моделювання, пошук і обробку даних. Система, керована повідомленнями, підтримує групу користувачів, що працюють над виконанням загального завдання. Системи, керовані даними, орієнтуються на доступ і маніпуляції з даними. Системи, керовані документами, здійснюють пошук і маніпулюють неструктурованою інформацією, заданої в різних форматах. Системи, керовані знаннями, забезпечують вирішення завдань у вигляді фактів, правил, процедур. На рівні даних, з якими ці системи працюють, умовно можна виділити: - оперативні; - стратегічні. Оперативні системи підтримки прийняття рішень призначені для негайного реагування на зміни поточної ситуації в управлінні фінансово-господарськими процесами компанії. Стратегічні системи орієнтовані на аналіз значних обсягів різнорідної інформації, що збираються з різних джерел. На рівні розв'язуваної задачі і області застосування виділяють системи підтримки прийняття рішень: · Першого класу; · Другого класу; · Третього класу. Системи підтримки прийняття рішень першого класу, що володіють найбільшими функціональними можливостями, призначені для застосування в органах державного управління вищого рівня (адміністрація президента, міністерства) і органах управління великих компаній (рада директорів корпорації) при плануванні великих комплексних цільових програм для обґрунтування рішень щодо включення в програму різних політичних, соціальних або економічних заходів і розподілу між ними ресурсів на основі оцінки їх вл яния на досягнення основної мети програми. Системи підтримки прийняття рішень цього класу є системами колективного користування, бази знань яких формуються багатьма експертами - фахівцями в різних областях знань. Системи підтримки прийняття рішень другого клас а є системами індивідуального користування, бази знань яких формуються безпосереднім користувачем. Вони призначені для використання державними службовцями середнього рангу, а також керівниками малих та середніх фірм для вирішення оперативних завдань управління. Системи підтримки прийняття рішень третього класу є системами індивідуального користування, адаптуються до досвіду користувача. Вони призначені для рішення часто зустрічаються прикладних задач системного аналізу та управління (наприклад, вибір суб'єкта кредитування, вибір виконавця роботи, призначення на посаду та ін.). Такі системи забезпечують отримання рішення поточної задачі на основі інформації про результати практичного використання рішень цієї ж завдання, прийнятих в минулому. Крім того, системи цього класу призначені для використання в торгових підприємствах, що торгують дорогими товарами тривалого користування, як засіб «інтелектуальної реклами», що дозволяє покупцеві вибрати товар на основі свого досвіду застосування товарів аналогічного призначення. На рівні архітектури системи підтримки прийняття рішень поділяються на: - функціональні системи підтримки прийняття рішень; - незалежні вітрини даних; - дворівневе сховище даних; - трирівневу сховище даних. Вони відрізняються організацією серверної сторони системи підтримки прийняття рішень. Характерною рисою функціональної системи є те, що аналіз здійснюється з використанням даних з оперативних систем. На стороні клієнта розташовується призначений для користувача інтерфейс системи підтримки прийняття рішень, а на серверної - джерела даних для задач прийняття рішень. Вітрина даних - база даних, функціонально-орієнтована і, як правило, містить дані по одному з напрямків діяльності організації. Вона відповідає тим же вимогам, що і сховище даних, але, на відміну від сховища, нейтрального до додатків, у вітрині даних інформація зберігається оптимізовано з точки зору вирішення конкретних завдань. Крім того, під вітриною даних іноді розуміють відносно невелика сховище даних або ж частина більш загального сховища даних, специфіковані для використання конкретним підрозділом в організації та / або певною групою користувачів. Якщо в корпоративній системі є дві "вітрини даних", то загальні дані, наявні в обох секціях одночасно, повинні бути представлені в секціях ідентично. Незалежні вітрини даних часто з'являються в організації історично і зустрічаються у великих організаціях з великою кількістю незалежних підрозділів, часто мають свої власні відділи інформаційних технологій. Сховище даних - предметно-орієнтований, інтегрований, незмінність, що підтримує хронологію набір даних, організований для цілей підтримки прийняття рішень, може складатися з декількох баз даних, має свою власну модель зберігання даних. Інформація, що надійшла в сховище, не видаляється, не змінюється. Дворівневе сховище даних будується централізовано для надання інформації в рамках компанії. Для підтримки такої архітектури необхідна фахівці в області сховищ даних. Це означає, що вся організація повинна погодити всі визначення і процеси перетворення даних. Трирівневе сховище даних являє собою єдиний централізований джерело корпоративної інформації. Вітрини даних представляють підмножини даних зі сховища, організовані для вирішення завдань окремих підрозділів компанії. Користувачі мають можливість доступу до детальним даними сховища, в разі, якщо даних у вітрині недостатньо, а також для отримання більш повної картини стану бізнесу. У більшості реальних випадків система прийняття рішень незалежно від класу і архітектури повинна допомогти особі, що приймає рішення, формалізувати його власні уявлення про цінності отриманих результатів і витрат на їх отримання. Головним в системі прийняття рішень є не обчислювальна частина, а технологічна підтримка процедури коректного вилучення і формалізації суб'єктивних вимог і переваг фахівців, а також процедури покрокового агрегування інформації під контролем аналітика. Система підтримки прийняття рішень - не більше ніж засіб технологічної підтримки процедури прийняття рішень, останнє слово завжди має залишатися за експертом. Тест по темі «Системи підтримки прийняття рішень» 1. Що характерно для ранніх систем підтримки прийняття рішень? a) можливість оперувати з неструктурованими або слабоструктурованих завданнями, на відміну від завдань, з якими має справу дослідження операцій b) оперує зі слабоструктурованих рішеннями; c) підтримує різноманітні стилі та методи вирішення, що може бути корисно при вирішенні задачі групою осіб, що приймають рішення; d) немає правильної відповіді 2. Які підсистеми входять в системи підтримки прийняття рішень? a) системи підтримки генерації рішень b) системи підтримки вибору рішень c) системи управління базами даних d) системи імітаційного моделювання e) немає правильної відповіді 3. Які методи використовують в системах підтримки прийняття рішень? a) метод аналітичних ієрархічних процесів b) метод Гаусса c) математичне моделювання d) метод аналітичних мережевих процесів e) немає правильної відповіді 4. Як можна класифікувати систему підтримки прийняття рішень? a) на рівні користувача b) в залежності від мови програмування c) на концептуальному рівні d) в залежності від області застосування 5. Яка система підтримки прийняття рішень дозволяє модифікувати рішення системи, що спираються на великі обсяги даних з різних джерел? a) активні b) кооперативні c) стратегічні d) оперативні e) керована даними f) немає правильної відповіді 6. До якого класу належить система підтримки прийняття рішення, чия база знань сформована багатьма експертами? a) першого b) другого c) третій 7. Які архітектури систем підтримки прийняття рішень бувають? a) незалежні вітрини даних; b) залежні вітрини даних; c) трирівневу сховище даних d) однорівневе сховище даних 8. Дані зберігаються в одному в єдиному екземплярі при архітектурі ..? a) трирівневу сховище даних b) дворівневе сховище даних c) функціональної системи d) чотирирівневої сховище даних Література по темі «Системи підтримки прийняття рішень»: 1. Абдрахімов Д, Іоффін А. Підтримка прийняття рішень: погляд на місце інформаційно-аналітичних технологій підтримки прийняття рішень в арсеналі банківського аналітика http://www.bizcom.ru/rus/bt/1997/nr4/10.htm 2. Горський П. Міфи і реальність використання наукових методів прийняття рішень в банківському бізнесі // Банківська справа №5, 2002. http://www.bizcom.ru/bank_business/2002-05/02.html 3. Кравченко Т. К., Наумова Н.Л. Сучасні інформаційні технології у розвитку комп'ютерних систем підтримки прийняття рішень. http://www.mesi.ru/ksit/k4sem24.zip 4. Ларічев О.І., Мошковіч Е.М. Якісні методи прийняття рішень. М. Наука. Фізматліт. 1996. 5. Лисянський К. Архітектури систем підтримки прийняття рішень. http://lissianski.narod.ru/index.html 6. Моїсеєв Н.Н. Передмову до книги Орловського С.А. Проблеми прийняття рішень при нечіткій вихідній інформації. М., Наука, 1981. 7. Пауер Д.Д. Коротка історія розвитку систем підтримки прийняття рішень. CorpSite.ru. http://corportal.ru/History/DataTech/DSS/DSS.aspx 8. Прийняття рішення: основні поняття і концепції http://de.nwpi.ru/courses/man/main.htm 9. Тоценко В. Системи підтримки прийняття рішень - ваш інструмент для правильного вибору // Компьютерра, № 34, 1998. http://www.computerra.ru/offline/1998/262/1520/ 10. Трахтенгерц Е.А. Комп'ютерна підтримка прийняття рішень. - М .: Сінтег, 1998.. Рекомендована література Штучний інтелект і інтелектуальні інформаційні системи - активно розвиваються і великі області досліджень і в рамках одного посібника просто неможливо розглянути всі питання і проблеми, якими вони займаються. Тут розглядалися основні напрямки та підходи. Для більш детального вивчення пропонується ознайомитися з рядом книг і посібників, перерахованих нижче: 1. Андрейчик, А. В. Інтелектуальні інформаційні системи: підручник для вузів. - М .: Фінанси і статистика, 2004. - 424 с. 2. Барсегян А.А., Купріянов М.С., Степаненко В.В., Холод І.І. Методи і моделі аналізу даних: OLAP і Data Mining. - СПб .: БХВ-Петербург, 2004. - с. 336. 3. Батиршін І. З., Недосекин А.О., Стецько А.А., Тарасов В.Б., Ярушкіна Н.Г. Нечіткі гібридні системи / Під. ред. Н.Г. Ярушкіной.- М .: ФІЗМАТЛІТ.-2007.- с. 208. 4. Вороновський Г.К. Махота К.В. Шів С.Н. Сергєєв С.А. Генетичні алгоритми, штучні нейронні мережі і проблеми віртуальної реальності. Х.: ОСНОВА, 1997. - с. 112. 5.Гаврилова Т.А., Хорошевський В.Ф. Бази знань інтелектуальних систем. СПб .: Пітер, 2001. - с. 384. 6. Гаскаров Д.В. Інтелектуальні інформаційні системи. Підручник для вузів. - М .: Вища школа, 2003. - с. 431. 7. Джарратано Д., Райлт Г. Експертні системи: принципи розробки та програмування, 4-е видання. / Пер. з англ. - М .: ТОВ «І.Д. Вільямс », 2007., - 1152 с. 8. Круглов В.В., Дли М.І., Голунь Р.Ю. Нечітка логіка і штучні нейронні мережі. М .: ФИЗМАТЛИТ, 2001. - с. 224. 9. Любарський Ю. Я. Інтелектуальні інформаційні системи /. - М.: Наука, 1990. - 227 с. 10. Макаров І.М., Топчеев Ю.І. Робототехніка: історія і перспективи - М .: Наука, Видавництво МАІ, 2003. - 349 с. 11. Міркес, Е.М. Нейроінформатика: Учеб. посібник для студентів. Красноярськ: ІСЦ КДТУ, 2002. - 347 с. 12. Нейроінформатика / А.Н.Горбань, В.Л.Дунін-Барковський, А.Н.Кірдін і ін. - Новосибірськ: Наука. Сибірське підприємство РАН, 1998. - 296 с. 13. Представлення і використання знань / Х. Уено. - М.: Мир, 1989. - 220 с. 14. Прикладні нечіткі системи: пров. з япон. / К.Асаі, Д. Ватада, С. Іваї і ін .; під редакцією Т. Тера, К. Асаи, М. Сугено. - М.: Мир, 1993. -368 с. 15. Рассел С., Норвіг П. Штучний інтелект: сучасний підхід, 2-е вид. - М .: Вільямс, 2006. - 1408 с. 16. Рутковська Д., Піліньскій М., Рутковський Л. Нейронні мережі, генетичні алгоритми та нечіткі системи. / Пер. з пол. І.Д. Рудинского. - М .: Гаряча лінія - Телеком, 2008. - 452 с. 17. Ручкін В.Н., Фулін В.А. Універсальний штучний інтелект та експертні системи - СПб .: БХВ-Петербург, 2009. - 240 с. 18. Уоссермен Ф. нейрокомп'ютерних техніка: Теорія і практика. - Пер. з англ., 1992. - 118 с. 19. Фогель Л., Оуенс А., Уолш М. Штучний інтелект і еволюційне моделювання. М .: Світ, 1969. - 230 с. 20. Частиков А.П., Гаврилова Т.А., Бєлов Д.Л. Розробка експертних систем. Середа CLIPS. - СПб .: БХВ-Петербург, 2003. - 608 с. 21. Шеховцов О. І. Подання знань: Учеб. допомога. - СПб. : ГЕТУ, 1997. - 56 с. 22. Ярушкіна Н.Г. Основи теорії нечітких і гібридних систем: Навчальний посібник М .: Фінанси і статистика, 2004.- 320 с. глосарій Основні визначення по темі «Історія розвитку штучного інтелекту» Штучний інтелект (Artificial Intelligence, AI) - наукова дисципліна, в рамках якого ставляться і вирішуються завдання апаратного або програмного моделювання тих видів людської діяльності, які традиційно вважаються інтелектуальними (подання знань, навчання, спілкування і т.п.). Інтелектуальна система - система або пристрій з програмним забезпеченням, що мають можливість за допомогою вбудованого процесора налаштовувати свої параметри в залежності від стану зовнішнього середовища. Евристика - процес пошуку рішень; прийом рішення задачі, заснований не на строгих математичних моделях і алгоритмах, а на міркуваннях, висхідних до "здоровому глузду", відображає особливості того, як такі завдання вирішує людина, коли він не користується строго формальними прийомами. Кібернетика - наука про управління, зв'язок і переробку інформації. Основним об'єктом дослідження кібернетики є абстрактні кібернетичні системи: від комп'ютерів до людського мозку і людського суспільства. Теорія ігор - математична теорія, передбачення результатів ігор, в яких учасники не мають повної інформації про наміри один одного. Теорія ігор використовується для опису процесів, що відбуваються на олігопольних ринках, і в теорії фірм. Теорія прийняття рішень - область дослідження, що вивчає закономірності вибору людьми шляхів вирішення різного роду завдань і досліджує способи пошуку найбільш вигідних з можливих рішень. Когнітивна психологія - напрям у психологічній науці, що вивчає залежність поведінки суб'єкта від пізнавальних процесів. Головне в когнітивної психології - виділення деяких загальних компонентів, структур, процесів, характерних для пізнання в цілому. В цьому плані когнітивна психологія - це сучасна психологія пізнавальних процесів. Основні визначення по темі «Напрямки досліджень в області штучного інтелекту» Нейрокібернетика - науковий напрямок, що вивчає основні закономірності організації і функціонування нейронів і нейронних утворень. Основним методом нейрокібернетики є математичне моделювання, при цьому дані фізіологічного експерименту використовуються в якості вихідного матеріалу для створення моделей. Нейрокомп'ютери - це системи, в яких алгоритм рішення задачі представлений логічною мережею елементів приватного виду - нейронів з повною відмовою від булевих елементів типу І, АБО, НЕ. Як наслідок цього введені специфічні зв'язки між елементами, які є предметом окремого розгляду. Нейрокомпьютинг - швидко розвиваючись область обчислювальних технологій, що стимулює дослідженнями мозку. Обчислювальні операції виконуються величезним числом порівняно простих, нерідко адаптивних процесорних елементів. Нейрокомпьютинг, за своїм походженням, абсолютно пристосований для порівняння образів, розпізнавання образів і синтезу систем управління. Робот - автоматичний пристрій з антропоморфних дією, яке частково або повністю замінює людини при виконанні робіт в небезпечних для життя умовах або при відносній недоступності об'єкта. Робот може управлятися оператором або працювати за заздалегідь складеною програмою. Використання роботів дозволяє полегшити або зовсім замінити людський працю на виробництві, в будівництві, при роботі з важкими вантажами, шкідливими матеріалами, а також в інших важких або небезпечних для людини умовах. Комп'ютерна лінгвістика (computational linguistics) - область використання комп'ютерів для моделювання функціонування мови в тих чи інших умовах або проблемних областях, а також сфера застосування комп'ютерних моделей мови в лінгвістиці та ін. Дисциплінах. Розпізнавання образів (Pattern recognition) - поділ образів в якомусь просторі на класи. Образ традиційно представляється у вигляді вектора виміряних величин. Розпізнавання мови (Speech recognition) - автоматичне розкладання звукового вигляду на фонеми і слова. Природна мова - в лінгвістиці будь-яку мову спілкування між людьми. Під природністю деякого мови розуміється наявність синонімії і омонімії слів і словосполучень, а також вільний порядок слів у реченні. Проблемна область інтелектуальної системи визначається предметною областю і розв'язуються в ній завданнями. Предметну область можна характеризувати описом області в термінах користувача, а завдання - їх типом. З точки зору розробника виділяються статичні і динамічні предметні області. Предметна область називається статичної, якщо описують її вихідні дані не змінюються в часі. При цьому похідні дані (виведені з вихідних) можуть з'являтися заново і змінюватися (не змінюючи при цьому вихідних даних). Якщо вихідні дані, що описують предметну область, змінюються за час виконання завдання, то предметну область називають динамічною. Основні визначення по темі «Представлення знань» Дані - це окремі факти, що характеризують об'єкти, процеси і явища предметної області, а також їх властивості; відомості, отримані шляхом вимірювання, спостереження, логічних або арифметичних операцій, представлені у формі, придатній для постійного зберігання, передачі і (автоматизованої) обробки. Знання - це закономірності предметної області (принципи, зв'язки, закони), отримані в результаті практичної діяльності і професійного досвіду, що дозволяють фахівцям ставити і вирішувати завдання в цій галузі; це добре структуровані дані, або дані про дані, або метадані. Поверхневі знання - знання про видимі взаємозв'язки між окремими подіями і фактами в предметної області. Глибинні знання - абстракції, аналогії, схеми, що відображають структуру і природу процесів, що протікають в предметної області. Ці знання пояснюють явища і можуть використовуватися для прогнозування поведінки об'єктів. Процедурні знання - знання, «розчинені» в алгоритмах. Декларативними знаннями вважаються пропозиції, записані на мовах подання знань, наближених до природного і зрозумілих неспеціалістам. Емпіричні знання - знання, які можуть видобуватися ІС шляхом спостереження за навколишнім середовищем. Поле знань - поле, в якому містяться основні поняття, що використовуються при описі предметної області, і властивості всіх відносин, які використовуються для встановлення зв'язків між поняттями. Поле знань пов'язано з концептуальною моделлю проблемної області, в якій ще не враховані обмеження, які неминуче виникають при формальному поданні знань в базі знань. Семантична мережа - це орієнтований граф, вершини якого - поняття, а дуги - відносини між ними. Фрейм - це абстрактний образ для представлення якогось стереотипу сприйняття. Основні визначення по темі «Нейронні мережі» Нейрон (біологічний) - клітина мозку, здатна генерувати електричний імпульс, в разі, коли сумарний потенціал перевищить критичну величину. З'єднуючись один з одним, нейрони утворюють мережу, по якій подорожують електричні імпульси, саме нейронні мережі мозку обробляють інформацію. При цьому «навчання» мережі і запам'ятовування інформації базується на налаштуванні значень ваг зв'язків між нейронами. Синапс (вага, синаптична вага) - міжнейронні з'єднання, односпрямована вхідні зв'язок нейрона, поєднана з виходом іншого нейрона. Аксон - вихідна зв'язок нейрона, за допомогою аксона нейрон передає власний вихідний сигнал. Штучна нейронна мережа (Artificial neural network) - це система, що складається з багатьох простих обчислювальних елементів, що працюють паралельно, функція яких визначається структурою мережі, силою взаємних зв'язків, а обчислення проводяться в самих елементах або вузлах. Нейронні мережі - клас моделей, заснованих на біологічної аналогії з мозком людини і призначених після проходження етапу так званого навчання на наявних даних для вирішення різноманітних завдань аналізу даних. Нейронна мережа - це процесор з масивним розпаралелюванням операцій, що володіє природною здатністю зберігати експериментальні знання і робити їх доступними для подальшого використання. Він схожий на мозок в двох відносинах: мережа набуває знання в результаті процесу навчання і для зберігання інформації використовуються величини інтенсивності міжнейронних з'єднань, які називаються синаптическими вагами. Нейрокомп'ютер - це обчислювальна система з архітектурою апаратного і програмного забезпечення, адекватної виконання алгоритмів, представлених в нейромережевому логічному базисі. Навчання нейронної мережі (Training) - цілеспрямований процес зміни міжшарових синаптичних зв'язків, итеративно повторюваний до тих пір, поки мережа не придбає необхідні властивості. Навчання з учителем або навчання контрольоване або навчання кероване (Supervised learning, Associative learning). Навчання з учителем передбачає, що для кожного вхідного вектора існує цільовий вектор, що представляє собою необхідний вихід. Разом вони називаються навчальною парою. Пред'являється вихідний вектор, обчислюється вихід мережі і порівнюється з відповідним цільовим вектором, різницю (помилка) за допомогою зворотного зв'язку подається в мережу і ваги змінюються відповідно до алгоритму, які прагнуть мінімізувати помилку. Вектори навчальної множини пред'являються послідовно, обчислюються помилки і ваги підлаштовуються для кожного вектора до тих пір, поки помилка по всьому навчальному масиву не досягне прийнятного рівня. Навчання без вчителя або самонавчання або навчання неконтрольоване або навчання некероване (Unsupervised learning, Self-organization) Алгоритм навчання без учителя підлаштовує ваги мережі так, щоб виходили узгоджені вихідні вектори, т. Е. Щоб пред'явлення досить близьких вхідних векторів давало однакові виходи. Процес навчання виділяє статистичні властивості навчальної множини і групує подібні вектори в класи. Перенавчання мережі (Over training, Overfitting) Якщо, в результаті навчання, нейронна мережа добре розпізнає приклади з навчальної множини, але не набуває властивість узагальнення, тобто не розпізнає або погано розпізнають будь-які інші приклади, крім навчальних, то кажуть, що мережа перенавчитися. Перенавчання - це результат надмірної підгонки мережі до навчальних прикладів. Збіжність процесу навчання (Coincidence of the learning algorithm). Метою процедури мінімізації є відшукання глобального мінімуму, досягнення його називається збіжністю процесу навчання. Завдання класифікації (Classification problem) полягає в розбитті об'єктів на класи, коли основою розбиття служить вектор параметрів об'єкта. Об'єкти в межах одного класу вважаються еквівалентними з точки зору критерію розбиття. Самі класи часто бувають невідомими заздалегідь і формуються динамічно (як, наприклад, в мережах Кохонена). Класи залежать від пропонованих об'єктів, і тому додавання нового об'єкта вимагає коригування системи класів. Кластеризація (Сlustering) - це один з методів аналізу даних, що дозволяють класифікувати багатовимірні спостереження, кожне з яких описується набором змінних X1, X2 ... Xn. Метою кластеризації є утворення груп схожих між собою об'єктів. Основні визначення по темі «Еволюційний моделювання» Еволюційне моделювання - напрямок в математичному моделюванні, що об'єднує комп'ютерні методи моделювання еволюції, а також кровоспоріднені по джерелу запозичення ідей інші напрямки в евристичному програмуванні. Включає в себе як розділи генетичні алгоритми, еволюційні стратегії, еволюційне програмування, штучні нейронні мережі, нечітку логіку. Генетичний алгоритм (Genetic algorithm, як напрям досліджень) - розділ еволюційного моделювання, запозичують методичні прийоми з теоретичних положень популяційної генетики. Являє собою свого роду модель машинного дослідження пошукового простору, побудовану на еволюційної метафорі. Характерні особливості: використання рядків фіксованої довжини для подання генетичної інформації, робота з населенням рядків, використання генетичних операторів для формування майбутніх поколінь. Генетичні алгоритми, будучи однією з парадигм еволюційних обчислень, являють собою алгоритми випадкового спрямованого пошуку для побудови (суб) оптимального вирішення даної проблеми, який моделює процес природної еволюції. Генетичні алгоритми (як метод) - адаптивні методи пошуку, які використовуються для вирішення задач функціональної оптимізації. Кросовер, схрещування (Crossover) - процедура або оператор в генетичних алгоритмах, що використовуються для отримання різноманітності в процесі відтворення. При одноточечного кросовері беруться дві хромосоми нащадка, на них випадковим чином вибирається точка, і для цієї точки відбувається обмін генетичного матеріалу нащадків. При двоточковому кросcовере відбувається те ж саме, тільки вибирається випадковим чином дві точки. Мутація (Mutation) - оператор в генетичних алгоритмах, призначений для внесення різноманітності в процес розмноження, з дуже малою ймовірністю двоичная мутація замінює біти в хромосомі випадковими бітами, значення цієї ймовірності є параметром генетичного алгоритму. Ген (Gene) в генетичних алгоритмах є основну одиницю інформації, визначальну характеристику особи. Наприклад, якщо ми використовуємо генетичний алгоритм для навчання нейронної мережі, то тоді в якості генів ми будемо використовувати ваги зв'язків між нейронами. Гени в реалізації генетичних алгоритмів зазвичай представляють собою бітові рядки фіксованої довжини. Генотип (Genotype) - уявлення особи в термінах генетичного алгоритму. Фенотип (Phenotype) - уявлення особи у вигляді, наявному в реальному світі. Хромосома, особина (Chromosome) - являє собою базовий елемент генетичного алгоритму. Вона являє собою набір генів, що описують параметри особини і однозначно визначає її. Наприклад, в завданню навчання нейронної мережі хромосома буде містити в собі повністю всі параметри. Зазвичай при реалізації генетичного алгоритму розмір хромосом від епохи до епохи не змінюється, хоча трапляються й винятки. Пристосованість, фітнес (Fitness) - параметр, що визначає наскільки добре дана особина відповідає вимогам. Вона розраховується для кожної особини на основі даних, закодованих в генотипі, і використовується для вибору найбільш пристосованих особин. Популяція (Population) - сукупність особин, що беруть участь в генетичних операціях. У класичних реалізаціях алгоритму її розмір постійний. Епоха (Еpoch) - один етап функціонування генетичного алгоритму. На ньому здійснюється обчислення пристосованості кожної особини популяції. Потім на підставі пристосованості відбираються хромосоми, які беруть участь у формуванні наступної епохи. Потім до них застосовуються генетичні операції, такі як схрещування, мутація і т.д. Основні визначення по темі «Нечіткі безлічі і нечітка логіка» Нечітка логіка (Fuzzy logic) умовивід з використанням нечітких множин або множин нечітких правил. Цей напрямок сходить до перших робіт по нечітким множинам, виконанню Лофті Заде (Lofti Zaden) в 1960-1970 рр. Невизначеність є невід'ємною частиною процесів прийняття рішень. Їх прийнято розділяти на три класи: · Невизначеність, пов'язана з неповнотою наших знань про проблему, через яку приймається рішення; · Невизначеність, яка виникає у зв'язку з непередбачуваністю реакції навколишнього середовища на наші дії; · Невизначеність - неточно розуміються мети безпосередньо самим ЛПР. Нечітке безліч А Í Х являє собою набір пар Нечітким числом називається опукле нормальне нечітка множина з кусочно-безперервною функцією приналежності, заданий на множині дійсних чисел. Лінгвістичну змінну можна визначити як змінну, значеннями якої є не числа, а слова або пропозиції природного (або формального) мови. Терм-безліччю (term set) називається безліч всіх можливих значень лінгвістичної змінної. Термом (term) називається будь-який елемент терм-множини. В теорії нечітких множин терм формалізується нечіткою множиною за допомогою функції приналежності. Дефазифікація (defuzzification) називається процедура перетворення нечіткої множини в чітке число. Фазифікації (fuzzification) називається процедура перетворення чітких значень в ступені впевненості. Нечітким логічним висновком називається отримання висновку у вигляді нечіткої множини, відповідного поточним значеннях входів, з використанням нечіткої бази знань і нечітких операцій. Нечіткою базою знань називається сукупність нечітких правил "Якщо - то", що визначають взаємозв'язок між входами і виходами досліджуваного об'єкта. Узагальнений формат нечітких правил такої: Якщо посилка правила, то висновок правила. Посилка правила або антецедент є твердження типу "x є низький", де "низький" - це терм (лінгвістичне значення), заданий нечітким безліччю на універсальній множині лінгвістичної змінної x. Квантіфікатори "дуже", "більш-менш", "не", "майже" і т.п. можуть використовуватися для модифікації термів антецедента. Висновок або наслідок правила є твердження типу "y є d", в якому значення вихідної змінної d може здаватися: - нечітким термо: "y є високий"; - класом рішень: "y є бронхіт" - чіткої константою: "y = 5"; - чіткої функцією від вхідних змінних: "y = 5 + 4 * x". Нечітка система - безліч нечітких правил, що перетворюють вхідні дані у вихідні. У найпростішому випадку експерт встановлює ці правила, в більш складному, - наприклад, нейросеть. Нечітке правило - умовне висловлювання виду «якщо X є A, то Y є B», де A і B нечіткі множини. Основні визначення по темі «Експертні системи» Експертні системи - це складні програмні комплекси, що акумулюють знання фахівців в конкретних предметних областях і тиражують ці знання для консультації менш кваліфікованих фахівців. Користувач - фахівець предметної області, для якого призначена система. Зазвичай його кваліфікація недостатньо висока, і тому він потребує допомоги і підтримки своєї діяльності з боку експертної системи. Інженер по знаннях - фахівець в області штучного інтелекту, який виступає в ролі проміжного буфера між експертом і базою знань. Синоніми: когнитологией, інженер-інтерпретатор, аналітик. Інтерфейс користувача - комплекс програм, що реалізують діалог користувача з ЕС як на стадії введення інформації, так і при отриманні результатів. База знань - ядро ЕС, сукупність знань предметної області, записана на машинний носій в формі, зрозумілою експерту і користувачу (зазвичай на деякій мові, наближеному до природного).Паралельно такому «людському» поданням існує БЗ у внутрішньому «машинному» поданні. Вирішувач - програма, що моделює хід міркувань експерта на підставі знань, наявних в БЗ. Синоніми: дедуктивна машина, машина виведення, блок логічного висновку. Підсистема пояснень - програма, що дозволяє користувачеві отримати відповіді на питання: «Як була отримана та чи інша рекомендація?» І «Чому система прийняла таке рішення?» Відповідь на питання «як» - це трасування всього процесу отримання рішення із зазначенням використаних фрагментів БЗ, тобто всіх кроків ланцюга умовиводів. Відповідь на питання «чому» - посилання на умовивід, безпосередньо передувала отриманому рішенню, тобто відхід на один крок назад. Розвинені підсистеми пояснень підтримують і інші типи питань. Інтелектуальний редактор бази знань - програма, що представляє інженеру по знаннях можливість створювати БЗ в діалоговому режимі. Включає в себе систему вкладених меню, шаблонів мови представлення знань, підказок і інших сервісних засобів, що полегшують роботу з базою. Рішення - процес і результат вибору способу і мети дій з ряду альтернатив в умовах невизначеності. Придбанням знань називається виявлення знань з джерел і перетворення їх в потрібну форму, а також перенесення в базу знань ІС. Джерелами знань можуть бути книги, архівні документи, вміст інших баз знань і т. П., Т. Е. Деякі об'єктивізовані знання, приведені до форми, яка робить їх доступними для споживача. Експертні знання - знання, які є у фахівців, але не зафіксовані в зовнішніх по відношенню до нього сховищах. Експертні знання є суб'єктивними. Формалізація. Процес формалізації знань, отриманих у експерта, складається з наступних кроків: вибір методу вимірювання нечіткості, отримання вихідних даних за допомогою опитування експерта, реалізація алгоритму побудови функції приналежності. Інтерпретація даних. Це одна з традиційних завдань для експертних систем. Під інтерпретацією розуміється процес визначення сенсу даних, результати якого повинні бути узгодженими і коректними. Зазвичай передбачається багатоваріантний аналіз даних. Діагностика. Під діагностикою розуміється процес співвідношення об'єкту з деяким класом об'єктів і / або виявлення несправності в деякій системі. Несправність - це відхилення від норми. Таке трактування дозволяє з єдиних теоретичних позицій розглядати і несправність устаткування в технічних системах, і захворювання живих організмів, і всілякі природні аномалії. Важливою специфікою є тут необхідність розуміння функціональної структури ( «анатомії») диагностирующей системи. Моніторинг. Основне завдання моніторингу - безперервна інтерпретація даних в реальному масштабі часу і сигналізація про вихід тих або інших параметрів за допустимі межі. Головні проблеми - «пропуск» тривожної ситуації і інверсна завдання «помилкового» спрацьовування. Складність цих проблем в розмитості симптомів тривожних ситуацій і необхідність обліку тимчасового контексту. Проектування. Проектування полягає в підготовці специфікацій на створення «об'єктів» із заздалегідь визначеними властивостями. Під специфікацією розуміється весь набір необхідних документів - креслення, пояснювальна записка і т. Д. Основні проблеми тут - отримання чіткого структурного опису знань про об'єкт і проблема «сліду». Для організації ефективного проектування і в ще більшому ступені перепроектування необхідно формувати не тільки самі проектні рішення, але і мотиви їх прийняття. Таким чином, в завданнях проектування тісно зв'язуються два основні процеси, виконуваних в рамках відповідної ЕС: процес виведення рішення і процес пояснення. Прогнозування. Прогнозування дозволяє передбачати наслідки деяких подій або явищ на підставі аналізу наявних даних. Прогнозують системи логічно виводять вірогідні наслідки з заданих ситуацій. У прогнозуючої системі зазвичай використовується параметрична динамічна модель, в якій значення параметрів «підганяються» під задану ситуацію. Виведені з цієї моделі слідства складають основу для прогнозів з ймовірними оцінками. Планування. Під плануванням розуміється знаходження планів дій, що відносяться до об'єктів, здатним виконувати деякі функції. У таких ЕС використовуються моделі поведінки реальних об'єктів з тим, щоб логічно вивести наслідки планованої діяльності. Навчання. Під навчанням розуміється використання комп'ютера для навчання якийсь дисципліни або предмету. Системи навчання діагностують помилки при вивченні якої-небудь дисципліни за допомогою ЕОМ і підказують правильні рішення. Вони акумулюють знання про гіпотетичного «учня» і його характерних помилках, потім в роботі вони здатні діагностувати слабкості в пізнаннях учнів і знаходити відповідні засоби для їх ліквідації. Крім того, вони планують акт спілкування з учнем залежно від успіхів учня з метою передачі знань. Управління. Під управлінням розуміється функція організованої системи, що підтримує певний режим діяльності. Такого роду ЕС здійснюють управління поведінкою складних систем відповідно до заданих специфікацій. Оптимізація - нахождене рішення, що задовольняє системі обмежень і максимізує або мінімізують цільову функцію. Основні терміни по темі «Системи підтримки прийняття рішень» Ухвалення рішення - це особливий вид людської діяльності, спрямований на вибір кращої з альтернатив. Головним завданням, яке доводиться вирішувати при прийнятті рішення, є вибір альтернативи, найкращою для досягнення певної мети, або ранжування безлічі можливих альтернатив за ступенем їх впливу на досягнення цієї мети. Процес прийняття рішень - отримання і вибір найбільш оптимальної альтернативи з урахуванням прорахунку всіх наслідків. При виборі альтернатив необхідно вибирати ту, яка найбільш повно відповідає поставленій меті, але при цьому доводиться враховувати велику кількість суперечливих вимог і, отже, оцінювати обраний варіант рішення за багатьма критеріями. Системи підтримки прийняття рішень (DSS, Decision Support System) є людино-машинними об'єктами, які дозволяють особам, які приймають рішення, використовувати дані, знання, об'єктивні і суб'єктивні моделі для аналізу і вирішення слабо структурованих і неструктурованих проблем. Сховище даних - предметно-орієнтований. Інтегрований, незмінність, що підтримує хронологію набір даних, організований для цілей підтримки прийняття рішень. Вітрина даних - спрощений варіант сховища даних, що містить тільки тематично об'єднаних дані. Вітрина даних, секція даних (Data Mart) - база даних, функціонально-орієнтована і, як правило, містить дані по одному з напрямків діяльності організації. Вона відповідає тим же вимогам, що і сховище даних, але, на відміну від сховища, нейтрального до додатків, у вітрині даних інформація зберігається оптимізовано з точки зору вирішення конкретних завдань. |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
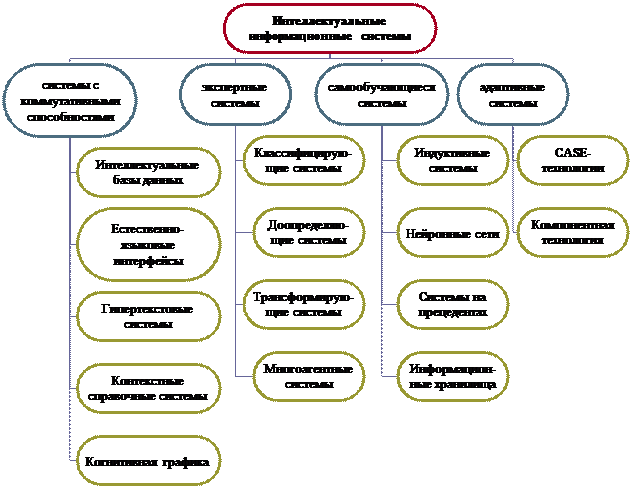
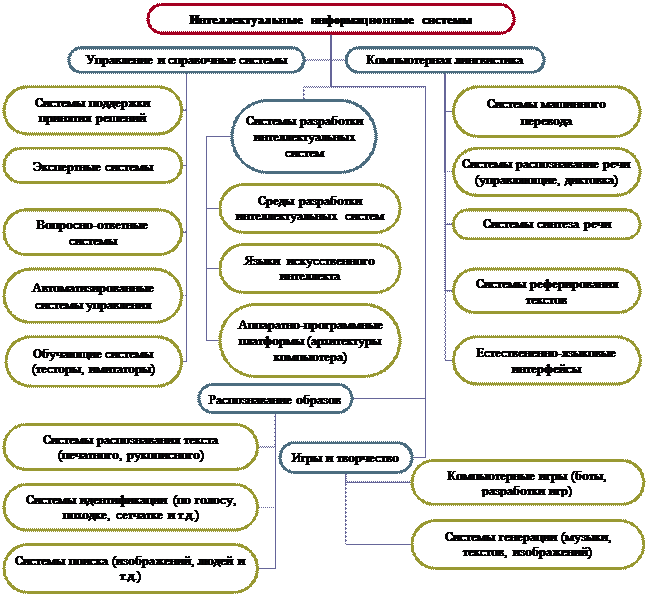

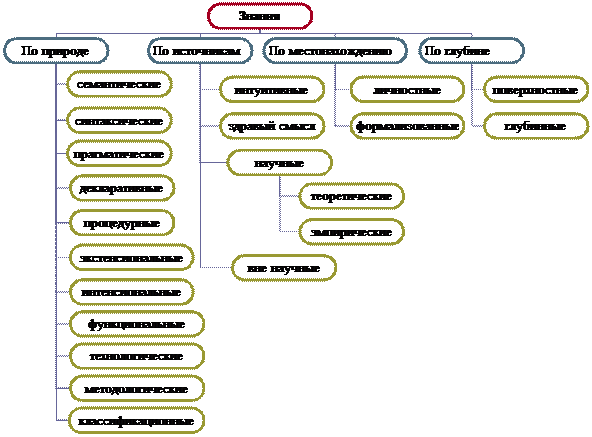
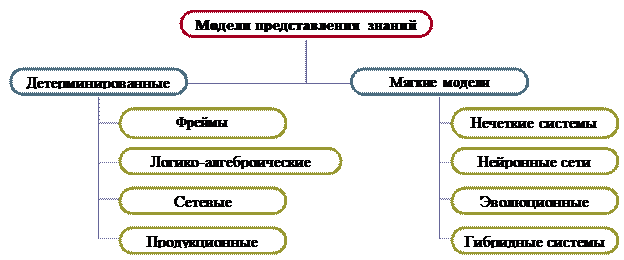
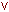 - або,
- або, 




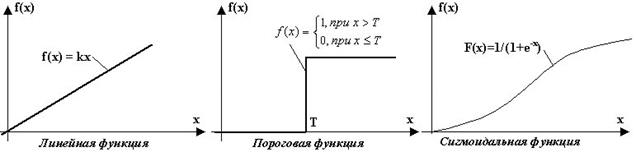
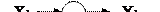
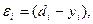
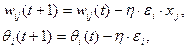
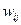 - вага зв'язку j-входу з i-нейроном,
- вага зв'язку j-входу з i-нейроном, 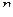 - коефіцієнт навчання, задається від 0 до 1,
- коефіцієнт навчання, задається від 0 до 1, 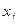 - вхідний значення,
- вхідний значення, 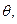 - порогове значення i-нейрона.
- порогове значення i-нейрона.
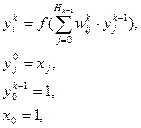
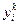 - вихід i-нейрона k-шару,
- вихід i-нейрона k-шару, 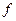 - функція активації,
- функція активації, 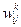 - синаптична зв'язок між j-нейроном шару k-1 і i-нейроном шару k,
- синаптична зв'язок між j-нейроном шару k-1 і i-нейроном шару k,  - вхідний значення.
- вхідний значення.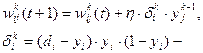
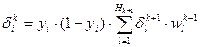 -
-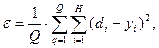
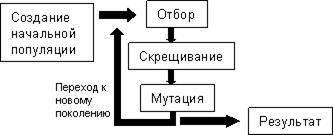

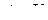 - це функція
- це функція  , Значення якої вказують, чи є
, Значення якої вказують, чи є 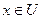 елементом множини A:
елементом множини A: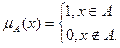
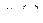 - ступенем приналежності елемента x нечіткій множині A.
- ступенем приналежності елемента x нечіткій множині A.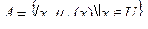
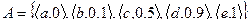 . Тоді елемент a не належить множині A, елемент b належить йому в малому ступені, елемент c більш-менш належить, елемент d належить в значній мірі, e є елементом множини A.
. Тоді елемент a не належить множині A, елемент b належить йому в малому ступені, елемент c більш-менш належить, елемент d належить в значній мірі, e є елементом множини A.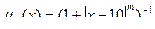 , де
, де 
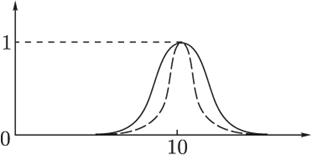
 таких точок в U, для яких величина
таких точок в U, для яких величина 
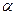 (
( 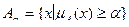 , де
, де 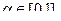
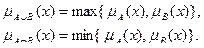
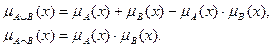
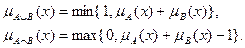
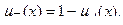
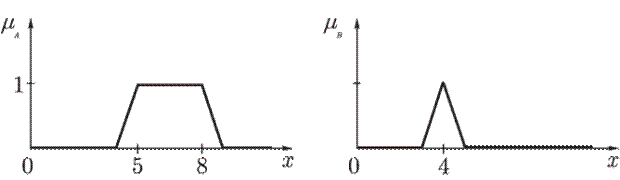
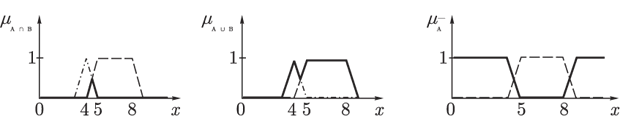
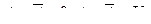
 і
і
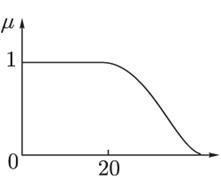
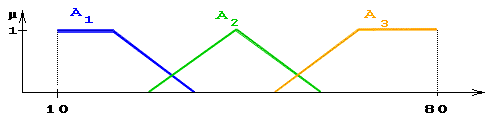
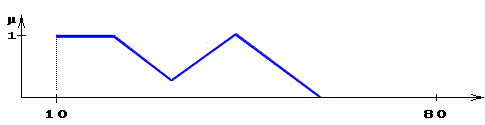
 , де
, де  Тобто, в деякому сенсі, наближення A. тоді з
Тобто, в деякому сенсі, наближення A. тоді з  і
і 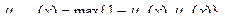
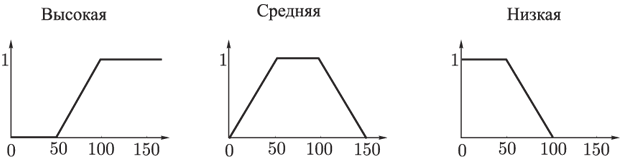
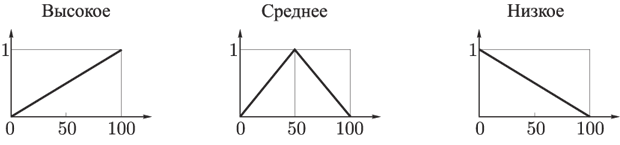
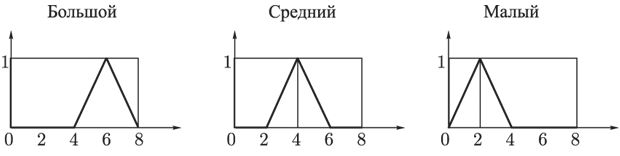
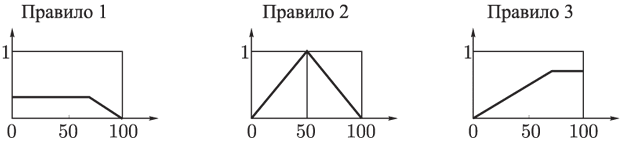
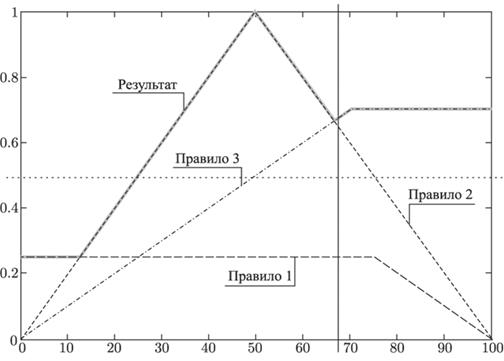

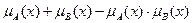
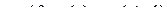

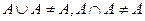
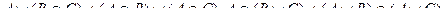
 6. На малюнку показані графіки функції приналежності нечітких множин
6. На малюнку показані графіки функції приналежності нечітких множин  - «Високе зростання» і
- «Високе зростання» і 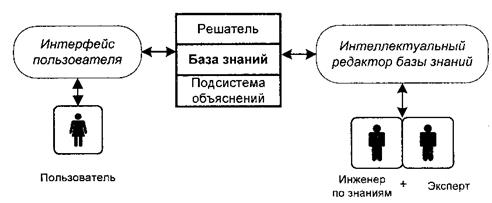





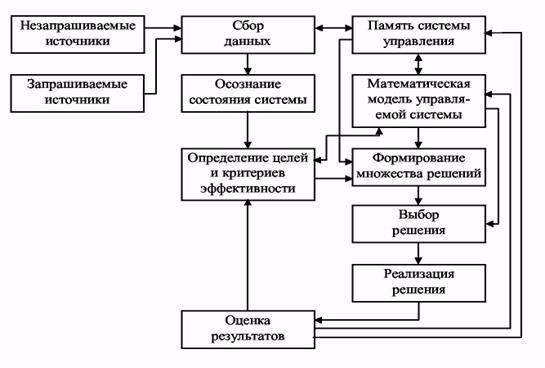
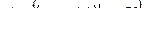 де х Î Х і
де х Î Х і 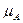 - функція приналежності, тобто
- функція приналежності, тобто 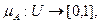 яка представляє собою деяку суб'єктивну міру відповідності елемента нечіткій множині і може приймати значення від нуля, який позначає абсолютну не приналежність, до одиниці, яка, навпаки, говорить про абсолютну приналежності елемента х нечіткій множині А.
яка представляє собою деяку суб'єктивну міру відповідності елемента нечіткій множині і може приймати значення від нуля, який позначає абсолютну не приналежність, до одиниці, яка, навпаки, говорить про абсолютну приналежності елемента х нечіткій множині А.- Визначення штучного інтелекту
- Історія розвитку штучного інтелекту
- Завдання штучного інтелекту
- Основні підходи до дослідження штучного інтелекту
- Основні напрямки досліджень в області штучного інтелекту
- Визначення інтелектуальної інформаційної системи
- Класифікація інтелектуальних систем
- Класифікація моделей подання знань
- Класифікація штучних нейронних мереж
- Одношарові штучні нейронні мережі
- Багатошарові нейронні мережі
- Завдання, які вирішуються нейронними мережами
- Схема функціонування генетичного алгоритму
- Види генетичних алгоритмів
- Теорія нечітких множин
- Модель експертних систем
- Класифікація експертних систем і оболонок експертних систем
- Засоби розробки експертних систем
- Структура систем підтримки прийняття рішень
- Класифікація систем підтримки прийняття рішень